SparkSQL 作为大数据处理领域中的重要工具,其性能优化对于提升可扩展性至关重要,在当今数据量呈爆炸式增长的时代,如何让 SparkSQL 能够高效地处理海量数据,并具备良好的可扩展性,成为了众多开发者和数据工程师关注的焦点。
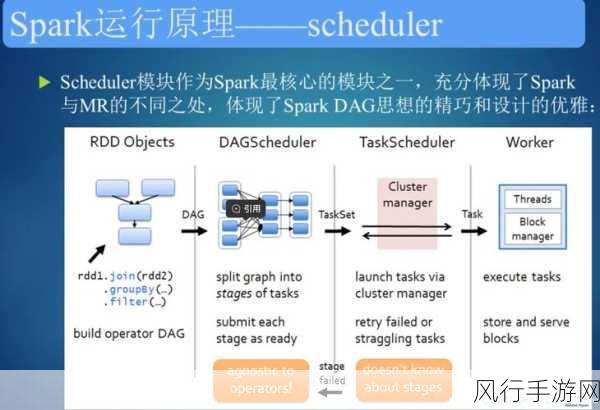
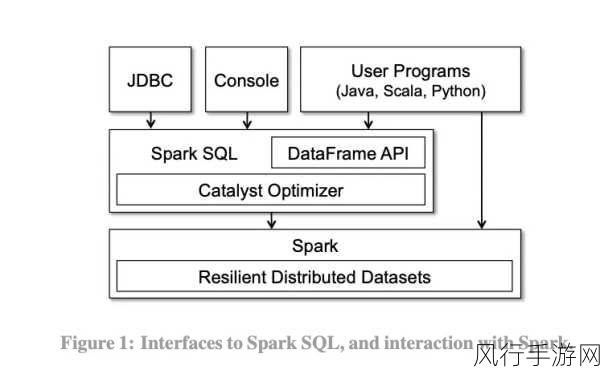
要理解 SparkSQL 优化如何提升可扩展性,我们得先明晰 SparkSQL 的工作原理和架构,SparkSQL 借助了 Spark 强大的分布式计算框架,将 SQL 查询转换为一系列的 RDD 操作,并通过优化器对查询计划进行优化,以提高执行效率,在实际应用中,由于数据的复杂性和多样性,往往需要我们从多个方面入手进行优化。
数据分区策略是提升 SparkSQL 可扩展性的关键之一,合理的分区可以确保数据在分布式环境中均匀分布,减少数据倾斜带来的性能瓶颈,根据常用的查询字段进行哈希分区,或者按照数据的范围进行范围分区,都能够有效地提高数据的并行处理能力。
缓存的使用也是不可忽视的优化点,对于频繁使用的数据或者计算结果,将其缓存起来可以避免重复计算,从而大幅提升查询性能,但需要注意的是,缓存并非越多越好,过度的缓存可能会导致内存资源的浪费和 GC 压力的增加。
索引的建立同样能够为 SparkSQL 的可扩展性带来显著的提升,类似于传统数据库中的索引,在 SparkSQL 中为经常用于查询和连接的字段创建索引,可以加快数据的检索速度,但创建索引也需要权衡其带来的存储成本和维护成本。
调整 Spark 配置参数也是优化的重要手段,合理设置 executor 的数量和内存大小,调整 shuffle 相关的参数等,都能够根据具体的硬件环境和数据特点来优化 SparkSQL 的执行性能。
要实现 SparkSQL 优化对可扩展性的提升,需要综合考虑数据分区、缓存使用、索引建立以及配置参数调整等多个方面,只有不断探索和实践,才能让 SparkSQL 在处理海量数据时游刃有余,为企业和组织的数据处理需求提供强大的支持。