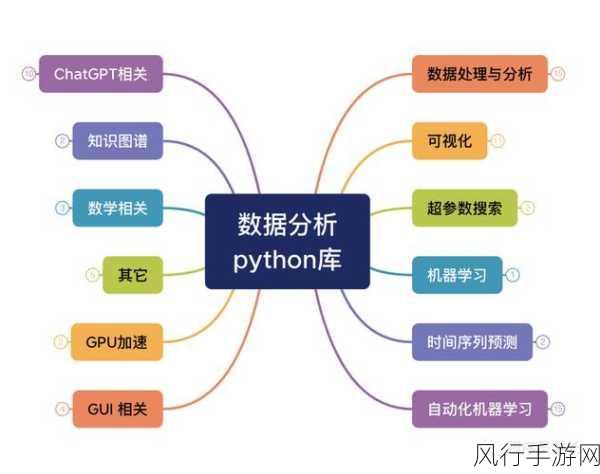
Python 数据挖掘,这一领域犹如一座蕴藏着无尽宝藏的矿山,等待着我们去挖掘和探索,在当今数字化时代,数据的价值日益凸显,而 Python 凭借其强大的功能和丰富的库,成为了数据挖掘的得力工具。
要掌握 Python 数据挖掘的技巧,了解数据的预处理至关重要,数据往往并非以我们期望的完美形式呈现,可能存在缺失值、异常值、重复数据等问题,这时,就需要运用各种方法对数据进行清洗和整理,使用pandas 库中的函数来处理缺失值,可以选择删除包含缺失值的行或列,也可以根据数据的分布情况进行填充,对于异常值的检测和处理,可以通过统计学方法或者基于业务逻辑来判断和修正。
特征工程是数据挖掘中的另一个关键环节,将原始数据转换为有意义的特征,能够显著提高模型的性能,对文本数据进行词袋模型或 TF-IDF 向量化处理,将连续数值型特征进行标准化或归一化操作,或者通过主成分分析(PCA)等方法进行降维。
选择合适的数据挖掘算法也是一门学问,分类问题可以使用决策树、朴素贝叶斯、支持向量机等算法;回归问题则可考虑线性回归、岭回归、随机森林回归等;聚类分析则有 K-Means、层次聚类等方法可供选择,在实际应用中,需要根据数据特点和问题需求,进行试验和比较,找到最适合的算法。

模型评估与调优是不可或缺的步骤,常用的评估指标如准确率、召回率、F1 值等,可以帮助我们判断模型的性能,通过调整算法的参数、增加训练数据量、尝试不同的特征组合等方法,不断优化模型,使其达到更好的效果。
可视化在数据挖掘中也发挥着重要作用,通过绘制图表,如柱状图、折线图、散点图等,可以直观地展示数据的分布和趋势,帮助我们发现数据中的规律和潜在问题。
Python 数据挖掘的技巧涵盖了数据预处理、特征工程、算法选择、模型评估与调优以及可视化等多个方面,只有熟练掌握这些技巧,并在实践中不断积累经验,才能在数据的海洋中挖掘出有价值的信息,为解决实际问题提供有力支持。