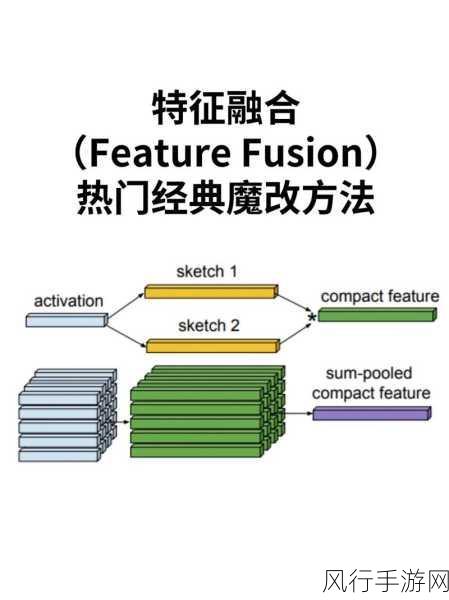
Flume 作为一个强大的数据收集工具,在与 Kafka 结合使用时,数据分片是一个关键的环节,数据分片的合理处理对于保障数据的高效传输和存储至关重要。
要理解 Flume Sink Kafka 中的数据分片,我们先来看看 Flume 和 Kafka 各自的特点,Flume 以其灵活的配置和可靠的数据采集能力而闻名,能够从各种数据源获取数据,而 Kafka 则是分布式的消息队列系统,具备高吞吐量、可扩展性和容错性。
Flume Sink Kafka 是如何实现数据分片的呢?Flume 在将数据发送到 Kafka 时,会根据一定的规则和策略对数据进行分类和分组,这些规则可以基于数据的特征,比如数据的类型、来源、时间戳等,通过这样的分类,数据被划分为不同的子集。
Kafka 会根据自身的分区机制来处理这些子集,Kafka 的分区机制能够确保数据在不同的分区中均匀分布,从而实现负载均衡和提高数据处理的效率,每个分区都可以在不同的节点上进行处理,进一步提升了系统的并行处理能力。
为了更好地控制数据分片的效果,还可以对 Flume 和 Kafka 的相关配置进行优化,调整 Flume 的缓冲区大小、批量发送数据的数量等参数,以及在 Kafka 中设置合适的分区数量和副本数量。
在实际应用中,需要根据具体的业务需求和系统的性能要求来灵活调整数据分片的策略,如果数据量较大且对实时性要求较高,可以增加分区数量和优化 Flume 的发送参数,以确保数据能够快速地被处理和存储。
Flume Sink Kafka 中的数据分片是一个复杂但又关键的环节,通过合理地配置和运用相关的策略,能够充分发挥 Flume 和 Kafka 的优势,实现高效的数据收集和处理,为各种业务应用提供有力的支持。