在当今数字化时代,数据的规模呈爆炸式增长,如何高效地处理大规模数据成为了众多开发者关注的焦点,C++ 作为一种强大的编程语言,其标准库中的 SET 容器在处理数据方面具有一定的特性和优势,C++ SET 能否胜任处理大规模数据的任务呢?
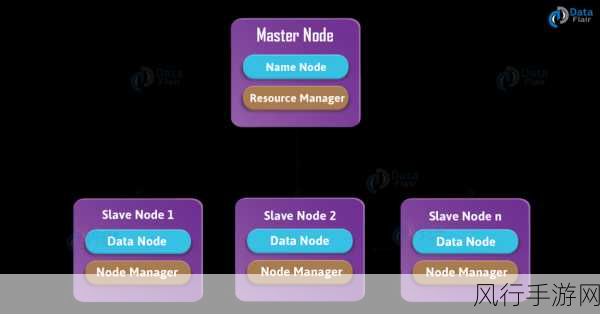
SET 是一种关联容器,其内部实现基于平衡二叉搜索树,这使得它在元素的插入、删除和查找操作上具有较高的平均效率,时间复杂度通常为 O(log n),这种特性使得 SET 在处理中等规模的数据时表现出色,但对于大规模数据,情况可能会有所不同。

在处理大规模数据时,内存的使用是一个关键因素,SET 容器需要为每个元素分配内存空间,并维护平衡二叉搜索树的结构,这可能会导致较大的内存开销,如果数据规模过大,可能会超出系统的可用内存,从而引发性能问题甚至程序崩溃。
SET 的插入和删除操作虽然平均效率较高,但在大规模数据的情况下,这些操作的实际耗时可能仍然较长,特别是在频繁进行插入和删除操作的场景中,性能可能会受到一定的影响。

这并不意味着 C++ SET 完全无法处理大规模数据,通过合理的优化和设计,可以在一定程度上提高其处理大规模数据的能力,可以采用分块处理的方式,将大规模数据分成若干小块,分别进行处理,从而降低单次操作的数据量。
还可以结合其他数据结构和算法,如哈希表、布隆过滤器等,来辅助 SET 进行数据处理,哈希表在查找操作上具有常数时间复杂度,但不支持有序性;布隆过滤器可以快速判断元素是否可能存在,从而减少不必要的查找操作。
在实际应用中,需要根据具体的业务需求和数据特点来选择是否使用 C++ SET 处理大规模数据,如果数据的有序性和唯一性要求较高,且对内存和性能的要求在可接受范围内,SET 可以是一个不错的选择,但如果对性能和内存要求极为苛刻,可能需要考虑更专门为大规模数据处理设计的数据结构和算法。
C++ SET 在处理大规模数据方面具有一定的潜力,但需要开发者充分了解其特性和限制,并结合实际情况进行优化和选择,以达到最佳的处理效果。