在当今数字化的时代,数据的价值日益凸显,Python 爬虫成为了获取数据的重要手段之一,要确保在线 Python 爬虫的稳定性并非易事,这需要我们从多个方面进行深入的思考和实践。
爬虫的稳定性受到众多因素的影响,网络环境的稳定性是至关重要的一点,不稳定的网络连接可能导致爬虫在抓取数据的过程中频繁中断,从而影响整个爬虫任务的进度和效果,在设计爬虫程序时,需要充分考虑网络波动的情况,采用适当的重试机制和错误处理策略,以确保在网络出现短暂问题时,爬虫能够自动恢复并继续工作。
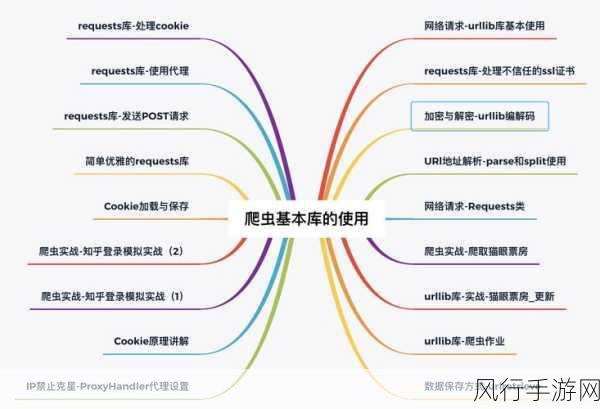
目标网站的反爬虫机制也是一个不可忽视的因素,许多网站为了保护自身的数据安全和服务器负载,会设置各种反爬虫措施,如限制访问频率、验证码验证、IP 封禁等,为了保障爬虫的稳定性,我们需要对目标网站的反爬虫规则进行深入研究,并遵循合法合规的原则,合理调整爬虫的行为,避免触发反爬虫机制,可以通过设置适当的请求间隔、使用代理 IP 等方式来降低被封禁的风险。
爬虫程序的代码质量和架构设计也对稳定性有着重要影响,高效、简洁、可维护的代码能够减少出错的概率,提高程序的运行效率,在编写爬虫代码时,要注重代码的规范性和可读性,合理运用面向对象编程、异常处理、日志记录等技术,以便在出现问题时能够快速定位和解决。
数据存储和处理环节也需要精心设计,如果在数据存储过程中出现错误,例如数据库连接异常、存储空间不足等,可能会导致爬虫程序崩溃,要确保数据存储的稳定性和可靠性,选择合适的数据库系统,并进行有效的数据备份和恢复策略。
保障在线 Python 爬虫的稳定性需要综合考虑网络环境、目标网站的反爬虫机制、代码质量和架构设计以及数据存储和处理等多个方面,只有在各个环节都做到精心规划和有效实施,才能让爬虫稳定、高效地为我们获取有价值的数据,在实际的开发过程中,我们还需要不断总结经验,根据具体情况灵活调整策略,以适应不断变化的网络环境和网站规则,从而使爬虫能够持续稳定地运行,为我们的数据分析和业务需求提供有力支持。