在当今大数据时代,Hive 作为一种常用的数据处理工具,其数据结构的合理运用对于数据处理的效率和性能至关重要,数据分区是 Hive 数据结构中的一个重要特性,能够有效地优化数据查询和管理。
Hive 中的数据分区是将数据按照特定的规则划分到不同的分区中,从而在查询时可以仅扫描相关分区,减少数据量,提高查询效率,如何在 Hive 数据结构中进行有效的数据分区呢?
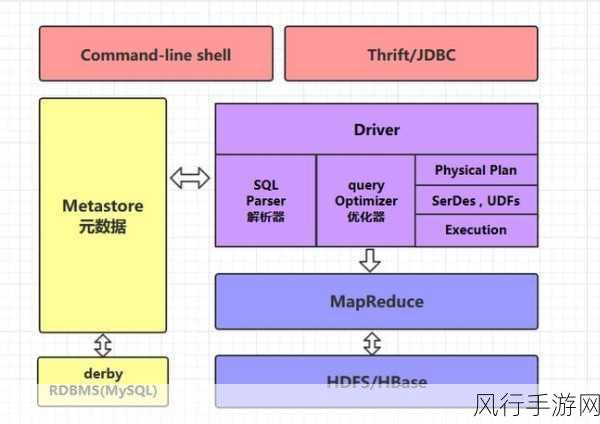
要理解 Hive 数据分区,我们需要先明确分区的目的,分区的主要目的是为了提高查询性能,通过将大规模的数据划分成较小的、可管理的部分,使得查询可以更快地定位到所需的数据范围。
我们看看 Hive 中常见的数据分区方式,一种常见的分区方式是基于日期进行分区,如果您的数据与时间相关,比如每日的销售数据,可以按照日期进行分区,将每天的数据存储在不同的分区中,这样,当您需要查询特定日期范围内的数据时,Hive 只需扫描对应日期的分区,而无需扫描整个数据集。
另一种常用的分区方式是基于字段值进行分区,如果您的数据中有一个表示地区的字段,您可以按照地区对数据进行分区,这样,当您需要查询特定地区的数据时,就能够快速定位到相应的分区。
在实施数据分区时,还需要注意一些要点,分区字段的选择非常关键,应该选择那些在查询中经常被用作筛选条件的字段,分区的数量也要合理控制,过多的分区可能会导致管理上的复杂性和性能下降。
对于分区表的维护也不能忽视,当有新的数据需要添加时,要确保按照既定的分区规则将数据插入到正确的分区中,定期对分区进行评估和优化,以适应数据的变化和业务需求的调整。
Hive 数据结构中的数据分区是一项强大的技术,能够显著提升数据处理的效率和性能,但要充分发挥其优势,需要我们在分区的设计、实施和维护等方面进行精心规划和管理,只有这样,才能让数据分区真正成为我们处理大数据的有力工具,为业务决策提供快速、准确的数据支持。