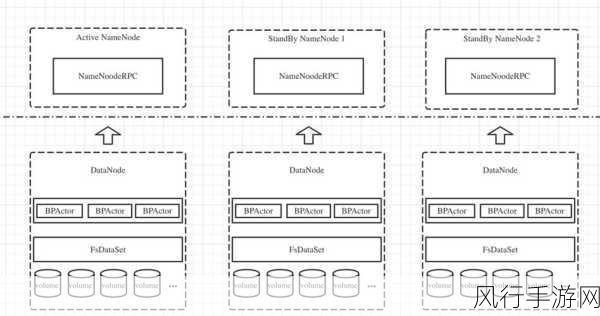
在大数据处理领域,Spark 作为一款强大的分布式计算框架,为数据处理提供了高效、可靠的解决方案,mapJoin 和缓存策略是 Spark 中两个重要的概念,它们之间存在着紧密的联系,对于提升数据处理性能起着关键作用。
mapJoin 是一种特殊的连接操作方式,相较于传统的连接方式,它能够在特定场景下显著提高处理效率,在一些情况下,当一个数据集较小而另一个数据集较大时,将小数据集广播到各个节点,然后在每个节点上进行本地连接操作,避免了数据的混洗和网络传输开销,从而大大加快了处理速度。
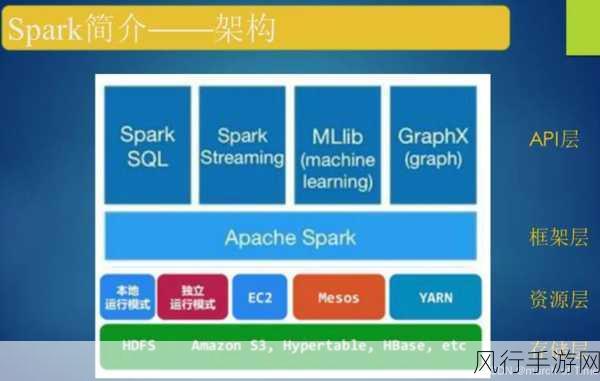
缓存策略则是为了提高数据的复用性和减少重复计算,通过将经常使用的数据或者计算结果缓存起来,后续的计算任务可以直接从缓存中获取数据,避免了重复计算和数据读取的时间消耗。
当 mapJoin 与缓存策略相结合时,能够产生更强大的效果,在执行 mapJoin 操作之前,如果能够预见到后续还会多次使用参与连接的小数据集,那么将其进行缓存就是一个明智的选择,这样,不仅在本次 mapJoin 中能够快速获取数据,在后续相关的计算中也能够迅速复用,进一步提升整体的处理效率。
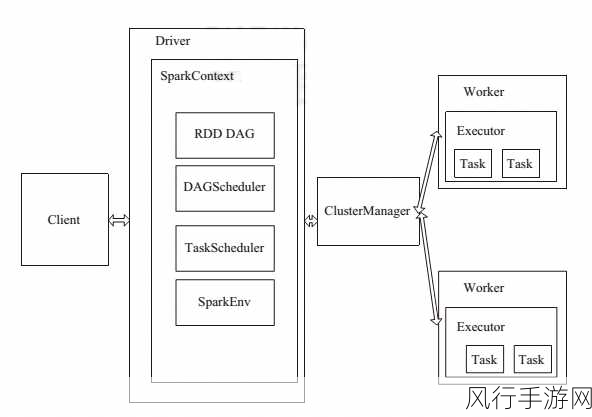
缓存策略还可以帮助优化 mapJoin 的资源使用,在内存资源有限的情况下,合理地选择缓存的数据以及缓存的方式,能够确保 mapJoin 操作能够顺利进行,而不会因为内存不足导致任务失败或者性能下降。
要充分发挥 mapJoin 与缓存策略的协同作用,并非一蹴而就,需要对数据的特点、计算任务的逻辑以及系统的资源状况有清晰的认识和准确的判断,对于变化频繁的数据,过度的缓存可能导致数据不一致性问题;而对于内存资源紧张的环境,不恰当的缓存设置可能会引发内存溢出等异常。
Spark 中的 mapJoin 和缓存策略是相辅相成的关系,深入理解和灵活运用它们的协同作用,能够帮助我们在大数据处理中实现更高效、更稳定的计算,为解决各种复杂的数据处理问题提供有力的支持,在实际应用中,不断地实践和总结经验,根据具体的业务需求和系统环境进行优化调整,是充分发挥它们优势的关键所在。