Hive 集群在企业数据处理和分析中扮演着至关重要的角色,如同任何复杂的技术系统一样,Hive 集群也可能会遭遇各种故障,这些故障不仅会影响业务的正常运行,还可能导致数据丢失或不准确等严重问题,掌握有效的故障处理方法对于维护 Hive 集群的稳定和可靠至关重要。
当 Hive 集群出现故障时,我们不能盲目地采取措施,而是需要有系统的分析和诊断步骤,第一步要明确故障的表现形式,是查询速度变慢、任务失败还是完全无法连接等,不同的故障表现可能指向不同的问题根源。
我们需要检查集群的资源使用情况,包括 CPU 利用率、内存占用、磁盘 I/O 等,如果某些资源过度消耗,可能是导致故障的原因之一,内存不足可能导致任务被强制终止,而 CPU 利用率过高可能意味着某些计算任务过于复杂或者存在死循环。
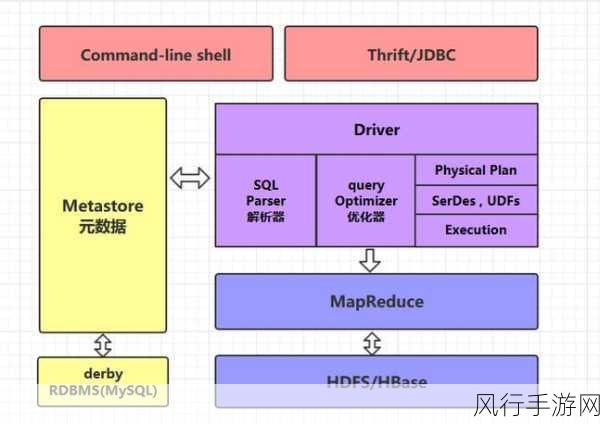
查看 Hive 集群的配置参数也是关键的一步,错误的配置参数可能会影响集群的性能和稳定性,连接池大小设置不当、并行度配置不合理等都可能引发故障。
对于常见的故障类型,如数据倾斜,我们需要深入分析相关任务的执行计划,通过查看任务的 Map 和 Reduce 阶段的分布情况,找出数据分布不均匀的节点,并采取相应的优化措施,比如重新分区、调整关联方式等。
网络问题也可能导致 Hive 集群故障,不稳定的网络连接可能会造成数据传输中断或者延迟,从而影响任务的执行,确保网络的稳定性和带宽的充足性是非常必要的。
如果故障仍然无法解决,查看 Hive 相关的日志文件是必不可少的,日志中通常会记录详细的错误信息和执行过程,有助于我们更准确地定位问题所在。
处理 Hive 集群故障需要我们具备全面的技术知识、系统的分析能力和丰富的实践经验,只有这样,才能迅速准确地找出故障根源,并采取有效的解决措施,确保 Hive 集群的正常运行,为企业的数据处理和分析工作提供坚实的保障。