在当今数字化的时代,数据成为了一种宝贵的资源,而爬虫技术则是获取这些数据的重要手段之一,许多网站为了保护自身的数据和服务质量,设置了各种反爬措施,对于使用 Python Selenium 进行爬虫的开发者来说,如何有效地处理这些反爬措施是一个关键的问题。
网站的反爬机制通常包括多种手段,例如限制访问频率、检测用户行为模式、验证请求来源等,当我们使用 Python Selenium 进行爬虫时,必须要对这些反爬机制有清晰的认识,才能有针对性地采取应对策略。
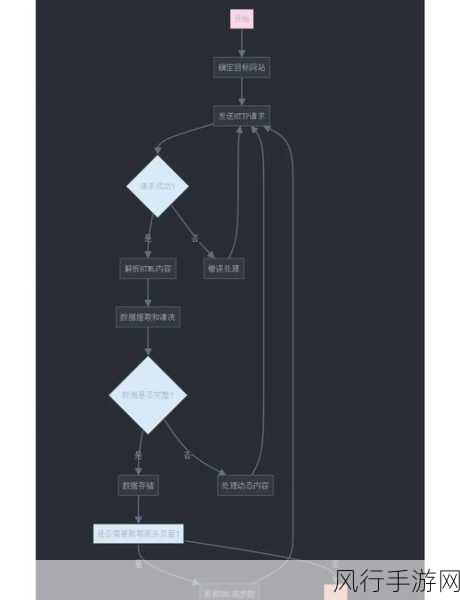
要处理反爬措施,第一步是模拟真实的用户行为,这意味着我们需要在操作浏览器时,尽量模仿人类的浏览习惯,比如随机的鼠标移动、页面滚动、点击间隔等,通过这样的方式,可以减少被网站检测为爬虫的可能性。
设置合理的请求间隔也是非常重要的,如果我们的爬虫请求发送得过于频繁,很容易被网站识别并封禁,可以根据目标网站的特点,设定一个适当的时间间隔,以避免触发反爬机制。

还有,使用代理 IP 也是一种常见的应对方法,当我们频繁从同一个 IP 地址发送请求时,容易引起网站的警觉,通过使用代理 IP,可以切换请求的来源,增加爬虫的隐蔽性。
在处理验证码时,需要根据具体情况选择合适的解决方案,对于简单的验证码,可以使用一些开源的识别库进行识别,而对于复杂的验证码,可能需要人工干预或者采用第三方验证码识别服务。
关注网站的 robots.txt 文件也是必要的,这个文件规定了网站允许和禁止爬虫访问的部分,遵守其规则可以避免不必要的麻烦。
处理 Python Selenium 爬虫的反爬措施需要综合运用多种技术和策略,并且要不断地进行测试和优化,只有这样,才能在合法合规的前提下,有效地获取所需的数据。
在实际的开发过程中,我们还需要时刻关注法律法规和道德规范,确保我们的爬虫行为不会对网站造成不良影响,也不会侵犯他人的合法权益,随着技术的不断发展,网站的反爬措施也在不断更新和加强,我们作为爬虫开发者,也要持续学习和探索新的方法,以适应不断变化的网络环境。