Python 以其简洁易读的语法和丰富的库,在数据处理领域得到了广泛应用,在处理大规模数据时,可能会遇到性能瓶颈,影响工作效率和应用的响应速度。
当面对复杂的数据处理任务时,Python 的一些特性可能会成为限制性能的因素,Python 的动态类型特性在运行时需要进行类型推断,这会增加一定的开销,Python 的全局解释器锁(GIL)也会在多线程环境下对并行处理造成一定的限制。
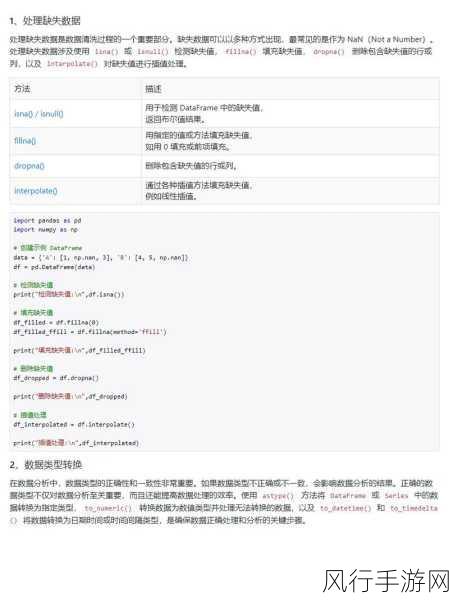
要解决 Python 数据处理的性能瓶颈,一种有效的方法是选择合适的数据结构和算法,对于常见的数据处理操作,如排序、搜索等,选择高效的算法可以显著提高性能,在需要快速查找元素时,使用哈希表结构而不是线性搜索。
合理使用向量化操作也是提升性能的关键,像 NumPy 这样的库提供了强大的向量化功能,可以一次性对大量数据进行操作,避免了循环带来的性能损耗。
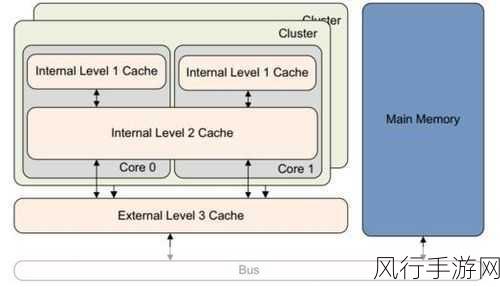
并行处理是突破性能瓶颈的重要手段,Python 中的 multiprocessing 库允许我们利用多核 CPU 进行并行计算,将任务分配到多个进程中同时执行,从而加快处理速度。
对于一些性能要求极高的场景,还可以考虑使用 C 或 C++扩展 Python,通过编写 C 或 C++代码,并将其与 Python 进行集成,可以充分利用底层语言的高效性能。
在实际应用中,我们需要根据具体的问题和数据特点,综合运用上述方法,不断优化和改进数据处理流程,以突破 Python 数据处理的性能瓶颈,实现更高效、更快速的数据处理。
虽然 Python 在数据处理中可能会面临性能瓶颈,但通过合理的技术选择和优化策略,我们能够充分发挥其优势,满足各种数据处理需求。