Kafka 作为一种高性能的分布式消息队列系统,在大数据处理和实时数据传输领域发挥着重要作用,而数据同步机制则是 Kafka 能够高效运行的关键所在。
Kafka 中的数据同步机制是保障数据可靠性和一致性的核心要素,它通过一系列复杂但精妙的设计,确保了数据在分布式环境中的准确传输和存储。
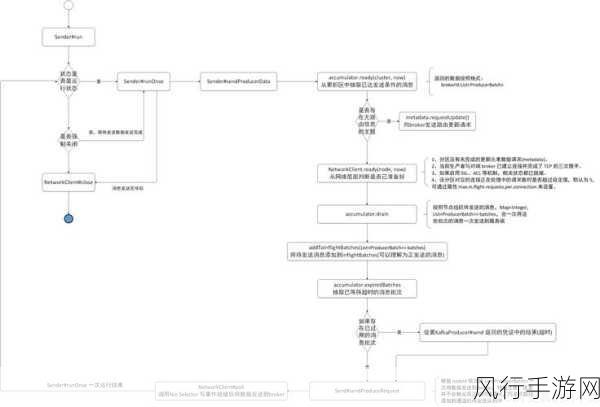
在 Kafka 中,常见的数据同步机制主要包括副本机制和 Leader 选举机制,副本机制是指为每个分区创建多个副本,这些副本分布在不同的节点上,当生产者向分区写入数据时,Leader 副本首先接收数据,并将其同步到其他副本中,这样,即使某个副本所在的节点出现故障,其他副本仍然能够提供数据服务,从而保证了数据的可用性和可靠性。
Leader 选举机制则是在 Leader 副本出现故障时,能够快速从其他副本中选举出新的 Leader 来继续处理数据,这种机制确保了数据处理的连续性,减少了因 Leader 故障而导致的数据中断和延迟。
Kafka 还采用了 ISR(In-Sync Replicas)机制来管理副本的同步状态,只有与 Leader 副本保持同步的副本才会被纳入 ISR 集合,如果某个副本落后于 Leader 副本太多,它将被从 ISR 集合中移除,以保证数据的一致性和可靠性。
为了实现高效的数据同步,Kafka 还利用了批量发送和压缩技术,批量发送可以减少网络开销,提高数据传输效率;而压缩技术则可以减少数据量,进一步提升数据传输和存储的性能。
Kafka 的数据同步机制是一个复杂但高效的体系,通过副本机制、Leader 选举机制、ISR 机制以及批量发送和压缩技术等的协同工作,为大数据处理和实时数据传输提供了坚实的基础,深入理解和掌握这些机制,对于充分发挥 Kafka 的性能和优势,构建稳定可靠的数据处理系统具有重要意义。