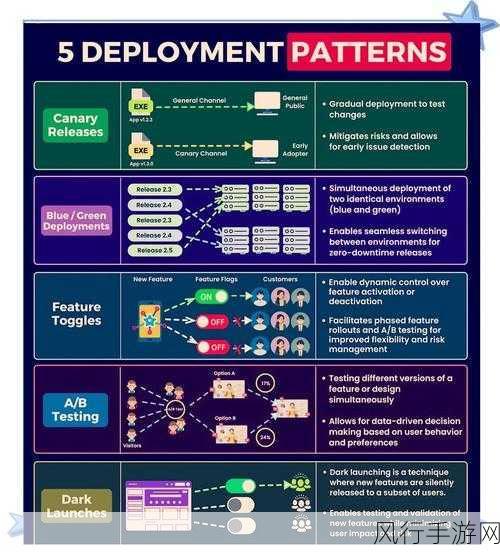
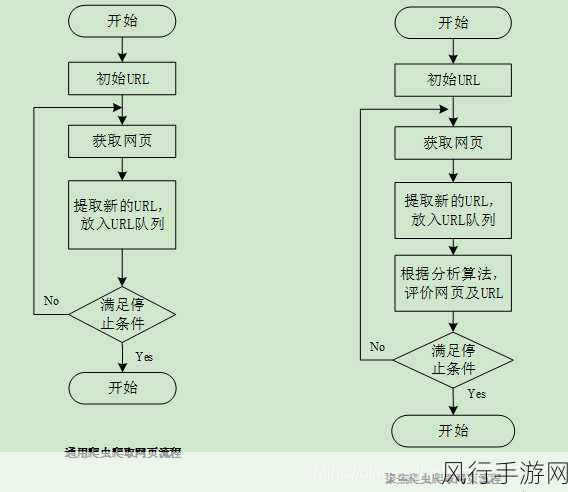
在当今数字化的时代,数据的获取和处理变得愈发重要,Python 凭借其强大的功能和丰富的库,成为了众多开发者进行爬虫操作的首选语言,而在 Python 爬虫中,掌握如何发送 Post 请求更是关键的一环。
Post 请求在与服务器进行交互时,能够传递更多的数据,并且在一些特定场景下,如提交表单、上传文件等,发挥着不可替代的作用。
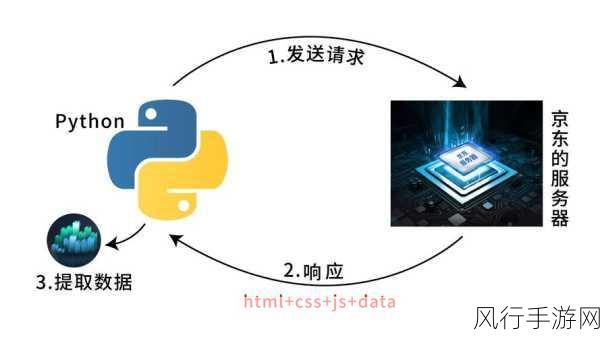
要实现 Python 爬虫中的 Post 请求发送,我们需要先导入相应的库。requests 库是一个非常好用且常见的选择,通过以下代码,我们可以轻松导入这个库:
import requests
就需要设置请求的 URL 以及要发送的数据,假设我们要向一个登录页面发送登录信息,URL 就是登录页面的地址,而数据则可能包括用户名和密码等信息。
url = 'https://example.com/login'
data = {
'username': 'your_username',
'password': 'your_password'
}在设置好这些基础信息后,就可以使用requests 库的post 方法来发送请求了。
response = requests.post(url, data=data)
发送请求后,我们会得到一个响应对象,通过这个响应对象,我们可以获取到服务器返回的各种信息,比如状态码、响应头、响应体等。
状态码能够告诉我们请求的处理结果是否成功,常见的成功状态码有 200,表示请求成功并得到了预期的响应,而如果出现 404,表示请求的资源未找到;403 则表示访问被禁止等。
响应头包含了关于服务器和响应的一些元数据,例如服务器的类型、响应的内容类型等。
响应体则是服务器返回的具体内容,可能是 HTML 页面、JSON 数据等,我们可以根据响应的内容类型来进行相应的处理。
如果响应是 HTML 页面,我们可以使用解析库如BeautifulSoup 来提取所需的信息;如果是 JSON 数据,则可以直接使用 Python 的json 模块进行解析。
在实际的爬虫开发中,发送 Post 请求时还需要注意一些问题,要处理可能出现的异常情况,如网络连接错误、服务器错误等,也要遵循网站的使用规则和法律法规,避免进行非法的爬虫活动。
Python 爬虫中的 Post 请求发送虽然看似复杂,但只要掌握了基本的原理和方法,并在实践中不断积累经验,就能够轻松应对各种数据获取的需求,为我们的数据分析和处理工作提供有力的支持,希望通过本文的介绍,能够让您对 Python 爬虫中 Post 请求的发送有更清晰的认识和理解,从而在实际应用中更加得心应手。