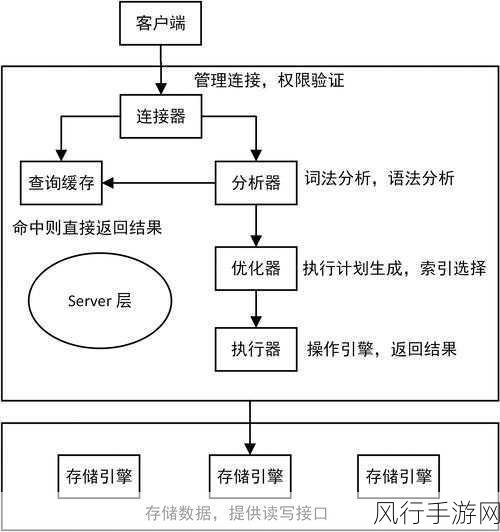
HBase 作为一种分布式的大数据存储系统,在处理海量数据方面具有出色的能力,而 Region 数量与数据量之间的关系,对于 HBase 系统的性能和效率有着至关重要的影响。
Region 是 HBase 中数据存储和管理的基本单元,当数据不断写入 HBase 时,会根据一定的规则进行分区,形成不同的 Region,数据量的增加会直接导致 Region 数量的变化。
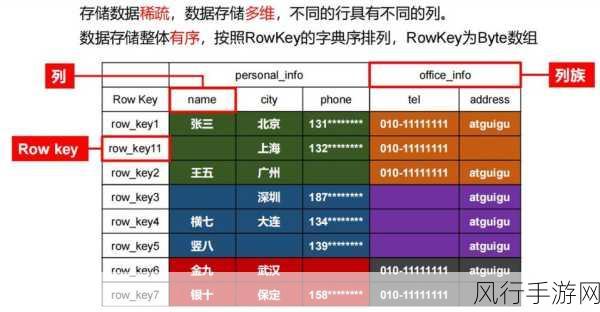
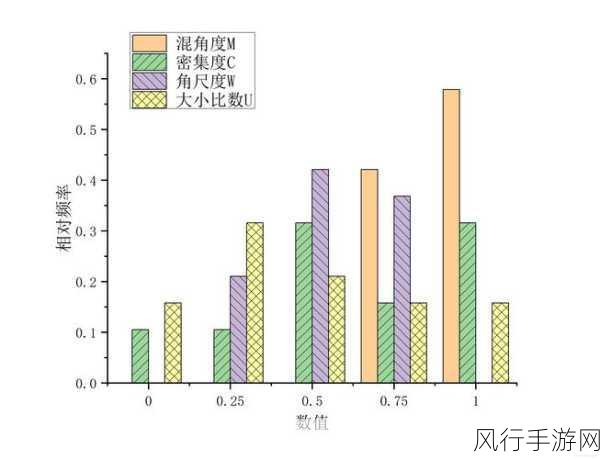
在较小的数据量情况下,Region 数量通常较少,这是因为数据量不足以触发系统进行更多的分区操作,数据的读写操作相对集中,系统的负载相对较低,性能表现可能较为出色,随着数据量的持续增长,单个 Region 所承载的数据量逐渐超过其合理的范围,为了保证系统的性能和稳定性,HBase 会自动进行分裂操作,将一个较大的 Region 分裂为两个或更多较小的 Region,这样一来,Region 的数量就会相应增加。
但 Region 数量并非越多越好,过多的 Region 会带来一系列问题,Region 的管理需要消耗一定的系统资源,包括内存和 CPU 等,过多的 Region 会增加系统的管理负担,导致资源的浪费和性能的下降,Region 之间的数据迁移和平衡操作也会变得更加频繁,这会影响数据的读写性能,过多的 Region 还可能导致元数据的膨胀,进一步影响系统的性能。
相反,Region 数量过少,也会带来不利影响,当数据量较大而 Region 数量不足时,单个 Region 中存储的数据量过大,这会导致数据的读写延迟增加,影响系统的响应速度,数据的分布不均衡也可能导致某些 Region 成为热点,承受过高的负载,从而影响整个系统的稳定性。
为了实现 HBase 系统的最优性能,需要根据实际的数据量和业务需求,合理地调整 Region 的数量,这需要对系统的负载、数据增长趋势、读写模式等因素进行综合考虑,通过有效的监控和分析,及时发现 Region 数量与数据量之间的不平衡,并采取相应的措施进行调整,如手动触发 Region 分裂或合并操作。
HBase 中 Region 数量与数据量之间存在着密切而复杂的关系,理解和把握这种关系,对于优化 HBase 系统的性能,提升数据存储和处理的效率具有重要意义,只有在实践中不断探索和总结,才能找到最适合特定业务场景的 Region 数量配置,充分发挥 HBase 的强大功能。