Kafka 作为一种高性能的分布式消息队列系统,在处理海量数据时,数据压缩是其提高存储效率和降低网络带宽消耗的关键手段之一,了解 Kafka 存储结构如何压缩数据对于优化系统性能和降低成本具有重要意义。
Kafka 中的数据压缩主要发生在消息的写入阶段,当生产者向 Kafka 发送消息时,可以选择启用压缩功能,并指定相应的压缩算法,常见的压缩算法包括 GZIP、Snappy 和 LZ4 等,这些算法在压缩效率和压缩和解压的性能之间有所权衡。
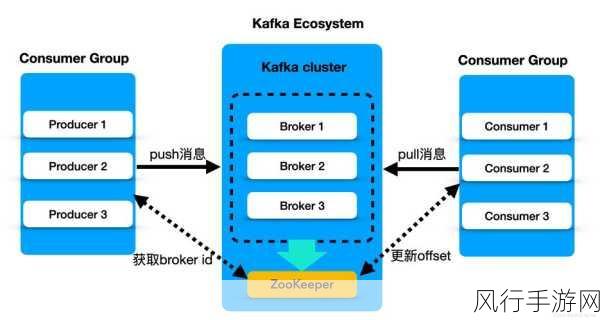
在 Kafka 的存储结构中,每个分区被划分为多个段(segment),每个段由一个索引文件和一个数据文件组成,当数据被写入时,会按照一定的规则分配到不同的段中,在压缩过程中,不是对每条单独的消息进行压缩,而是对一批消息进行压缩处理,这样可以提高压缩效率,减少压缩和解压的开销。
Kafka 之所以能够有效地压缩数据,还得益于其消息的存储格式,消息在存储时,会包含一些元数据信息,如消息的偏移量、时间戳等,在压缩时,这些元数据信息也会被合理地处理,以减少不必要的存储空间占用。
Kafka 还会根据数据的特点和压缩算法的特性,动态地调整压缩的参数和策略,如果数据的重复度较高,可能会选择压缩比更高的算法;如果对数据的处理速度要求较高,则会选择解压速度更快的算法。
为了确保压缩后的数据能够被正确读取和处理,Kafka 在读取数据时,会自动进行解压操作,解压过程会根据压缩算法和相关的元数据信息,将压缩的数据还原为原始的消息内容。
Kafka 存储结构中的数据压缩是一个复杂但高效的过程,通过合理选择压缩算法、优化存储格式和动态调整压缩策略,Kafka 能够在保证数据可靠性和处理性能的前提下,有效地节省存储空间和网络带宽,为大规模数据处理提供了强大的支持,对于开发者和运维人员来说,深入理解 Kafka 的数据压缩机制,有助于更好地优化系统配置,提升系统的整体性能和效率。