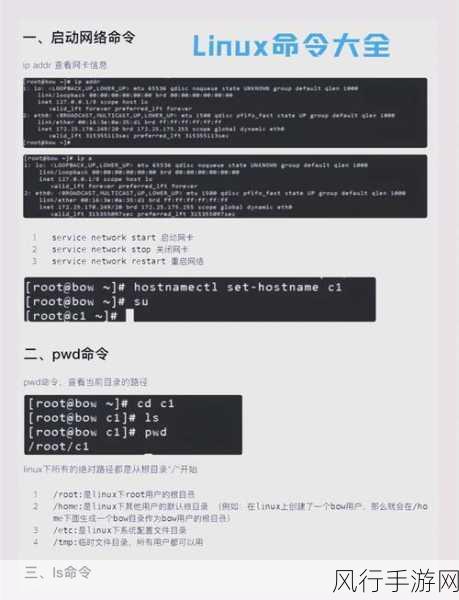
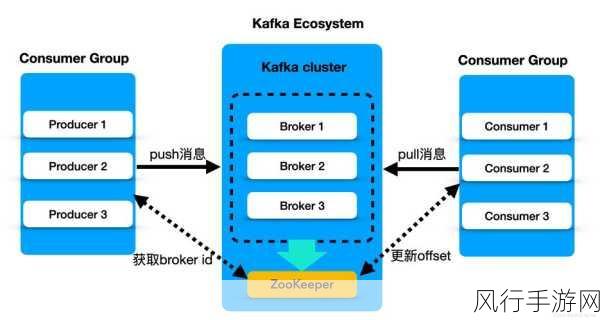
Presto 作为一款高性能的分布式查询引擎,在大数据处理领域中展现出了诸多令人瞩目的优势,它能够快速处理海量数据,为企业和开发者提供高效的数据查询和分析服务。
Presto 能够实现快速的数据查询,这得益于其优秀的架构设计和优化算法,与传统的查询引擎相比,Presto 能够充分利用分布式计算的能力,将查询任务分解到多个节点上并行执行,从而大大缩短了查询的响应时间,无论是处理结构化数据还是半结构化数据,Presto 都能够游刃有余,迅速返回准确的结果。
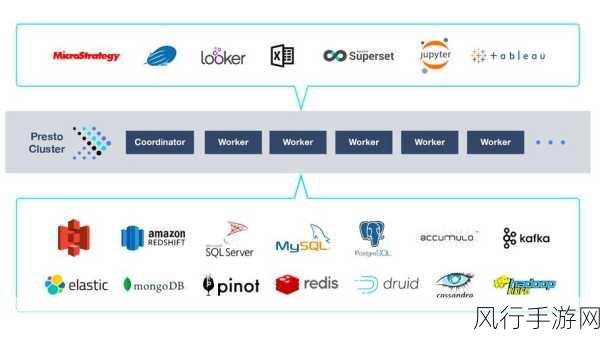
Presto 具有出色的扩展性,在数据量不断增长、业务需求不断变化的情况下,Presto 可以轻松地通过增加节点来扩展其处理能力,这种灵活的扩展方式使得企业无需担心因数据规模的扩大而导致查询性能的下降,能够有效地应对未来的业务发展和数据增长。
Presto 支持多种数据源的连接,它可以与 Hive、MySQL、Oracle 等常见的数据库和数据存储系统进行无缝集成,使得用户能够在一个统一的平台上对来自不同数据源的数据进行查询和分析,这不仅减少了数据迁移的成本和复杂性,还提高了数据的利用率和价值。
Presto 的使用门槛相对较低,它提供了简洁直观的查询语法,使得开发人员和数据分析师能够快速上手,无需花费大量的时间和精力去学习复杂的操作和配置,Presto 还拥有活跃的社区和丰富的文档资源,为用户在使用过程中遇到的问题提供了及时有效的支持和解决方案。
Presto 还具备良好的容错性,在分布式环境中,节点故障是不可避免的,但 Presto 能够自动检测和处理这些故障,确保查询任务的正常执行,即使在部分节点出现问题的情况下,Presto 也能够重新分配任务,保证查询结果的完整性和准确性。
Presto 分布式查询引擎凭借其快速查询、出色的扩展性、多数据源支持、低使用门槛和良好的容错性等优势,成为了大数据处理领域中不可或缺的重要工具,它为企业和开发者提供了高效、便捷和可靠的数据查询和分析解决方案,帮助他们从海量数据中快速获取有价值的信息,做出更加明智的决策,随着大数据技术的不断发展和应用场景的不断拓展,相信 Presto 在未来将会发挥更加重要的作用,为推动数据驱动的创新和发展贡献更多的力量。