在当今数字化的时代,数据库管理系统扮演着至关重要的角色,Oracle 数据库作为广泛使用的数据库之一,其功能强大且复杂,DISTINCT 关键字在数据处理和查询中经常被用到,它能够帮助我们获取不重复的数据记录。
Oracle 数据库中的 DISTINCT 是如何实现的呢?这背后涉及到一系列的机制和算法。
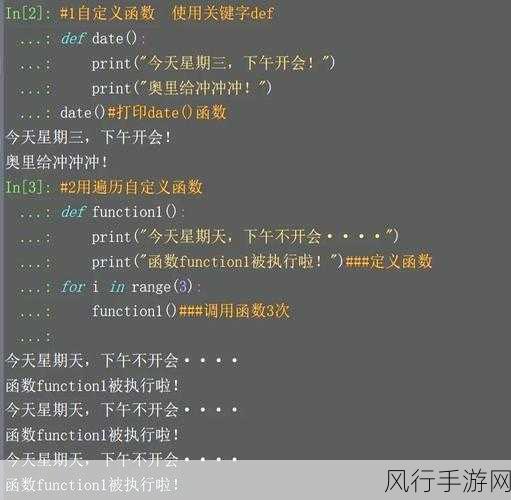
要理解 DISTINCT 的实现,首先需要明确其作用,DISTINCT 主要用于在查询结果中消除重复的行,当我们执行一个包含 DISTINCT 关键字的查询时,Oracle 数据库会对查询结果进行去重操作。
Oracle 数据库在处理 DISTINCT 时,通常会采用哈希表或者排序的方式,哈希表是一种高效的数据结构,它能够快速地判断一个元素是否已经存在,在使用哈希表的情况下,数据库会将每一行数据的相关字段计算哈希值,并将其存储在哈希表中,当遇到新的行时,计算其哈希值并与已有的哈希值进行比较,如果相同,则表示是重复的行,不会被添加到最终的结果集中。

而当数据量较大或者哈希冲突较多时,Oracle 数据库可能会选择排序的方式来实现 DISTINCT,通过对数据进行排序,相同的行会相邻排列,然后可以方便地去除重复的行。
Oracle 数据库还会考虑索引的存在来优化 DISTINCT 的执行,如果查询涉及的字段有合适的索引,数据库可以利用索引来更快速地进行去重操作。
在实际应用中,使用 DISTINCT 时需要谨慎,因为它可能会带来性能开销,特别是在处理大量数据时,如果不必要地使用 DISTINCT,可能会导致查询效率低下。
为了优化包含 DISTINCT 的查询,我们可以考虑以下几点:确保只在真正需要去重的字段上使用 DISTINCT,如果可能的话,尽量先对数据进行筛选和限制,减少需要处理的数据量,合理创建和利用索引,以提高查询的性能。
Oracle 数据库中的 DISTINCT 是一个强大而有用的功能,但要充分发挥其作用并避免潜在的性能问题,需要我们对其实现原理有深入的理解,并在实际应用中进行合理的运用和优化。