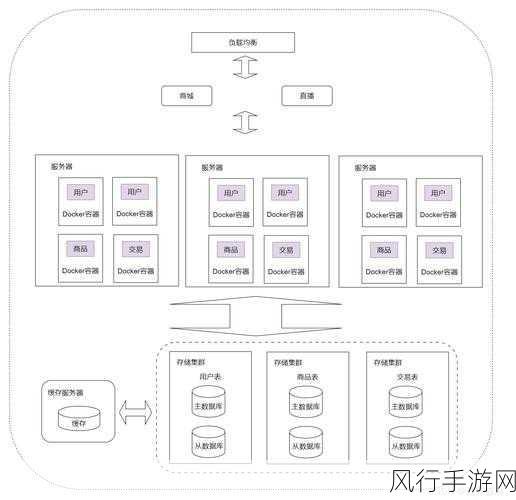
在当今数字化时代,数据处理的高效性和及时性至关重要,Kafka 作为一款强大的分布式消息队列系统,在处理大量数据时可能会遇到数据积压的情况,这将直接影响系统的响应速度,让我们深入探讨如何有效地处理 Kafka 数据积压,以显著提高响应速度。
Kafka 数据积压问题的产生通常是由多种因素共同作用所致,消费者处理速度过慢,可能是由于代码逻辑复杂、资源分配不足或者外部依赖的系统出现故障,生产者发送数据的速度过快,超过了消费者的处理能力,也会导致数据积压,如果 Kafka 集群的配置不合理,如分区数量不足、副本数设置不当等,同样会引发这一问题。
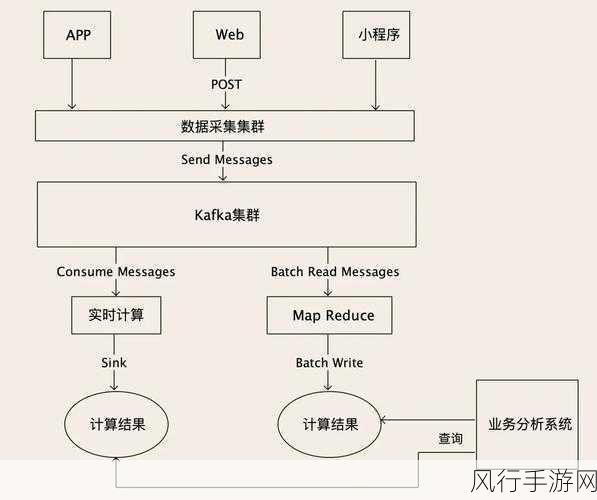
要解决 Kafka 数据积压问题并提高响应速度,第一步是优化消费者的处理逻辑,通过对代码进行审查和优化,减少不必要的计算和操作,提高处理效率,合理分配系统资源,确保消费者能够充分利用硬件性能来处理数据。
增强消费者的并行处理能力也是关键之一,可以通过增加消费者的数量或者使用多线程的方式来同时处理多个分区的数据,从而加快数据的消费速度。
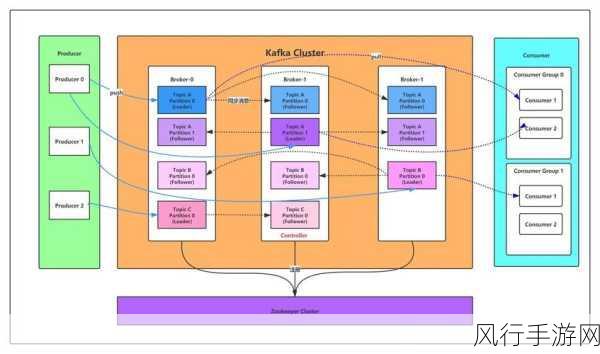
对 Kafka 集群进行合理的配置调整不可或缺,根据实际的业务需求和数据量,适当增加分区数量,使得数据能够更均匀地分布在各个分区中,提高处理效率,合理设置副本数,确保数据的可靠性和可用性。
监控和预警机制的建立对于及时发现和解决数据积压问题至关重要,通过实时监控 Kafka 集群的各项指标,如数据积压量、消费者处理速度、生产者发送速度等,一旦出现异常情况能够及时发出警报,以便相关人员采取措施进行处理。
还需要定期对 Kafka 系统进行性能测试和优化,模拟不同的业务场景和数据量,评估系统的性能表现,发现潜在的问题并进行针对性的优化。
解决 Kafka 数据积压问题并提高响应速度需要综合考虑多个方面,从优化消费者处理逻辑、增强并行处理能力、合理配置集群,到建立监控预警机制和定期进行性能测试优化,每个环节都需要精心设计和实施,才能确保 Kafka 系统能够高效稳定地运行,为业务提供有力的支持。