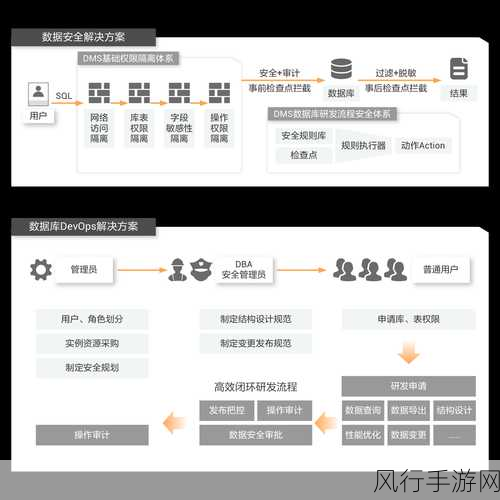
Kotlin 作为一种现代编程语言,尾递归函数在其功能中占据着重要的一席之地,就如同任何技术特性一样,Kotlin 尾递归函数也并非毫无限制。
尾递归函数是一种在函数调用自身的过程中,通过优化避免栈溢出错误的编程方式,在 Kotlin 中,尾递归函数能够极大地提高程序的性能和可读性,但它也有着自身的一些约束和条件。
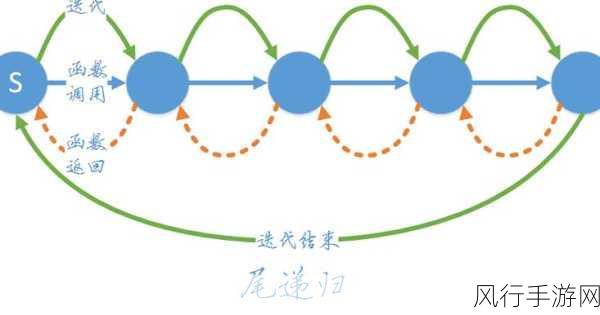
其中一个显著的限制在于,尾递归函数需要满足特定的语法和结构要求,函数必须明确地标记为tailrec 关键字,以告知编译器进行尾递归优化,如果没有正确标记,编译器将无法识别并执行相应的优化,从而可能导致性能问题。
尾递归函数中的递归调用必须是整个函数体的最后一个操作,也就是说,在递归调用之后,不能再有其他的计算或操作,否则,编译器无法将其视为尾递归,优化也就无从谈起。

尾递归函数的参数传递也有一定的限制,由于尾递归优化的本质是通过重复使用当前的栈帧来替代不断创建新的栈帧,所以参数的传递和处理方式需要符合一定的规则,如果参数的处理过于复杂或者不符合尾递归的模式,可能会影响优化效果。
尾递归函数在处理复杂的逻辑和大规模的数据时,可能会出现一些难以预料的问题,如果递归的深度过大,即使进行了优化,也可能会因为其他资源的消耗而导致性能下降或者出现错误。
尽管 Kotlin 尾递归函数存在这些限制,但只要开发者充分理解其工作原理和限制条件,合理地运用尾递归函数,仍然能够在很多场景中发挥出其独特的优势,提升程序的效率和质量。
在实际开发中,我们需要根据具体的业务需求和代码逻辑,谨慎地选择是否使用尾递归函数,对于一些复杂的情况,可能需要结合其他编程技术和算法来达到最佳的效果。
Kotlin 尾递归函数是一个强大的工具,但需要我们在使用时充分考虑其限制,以确保能够充分发挥其优势,为我们的编程工作带来便利和效率的提升。