Spark 计算框架作为大数据处理领域的重要利器,具有诸多令人瞩目的优势。
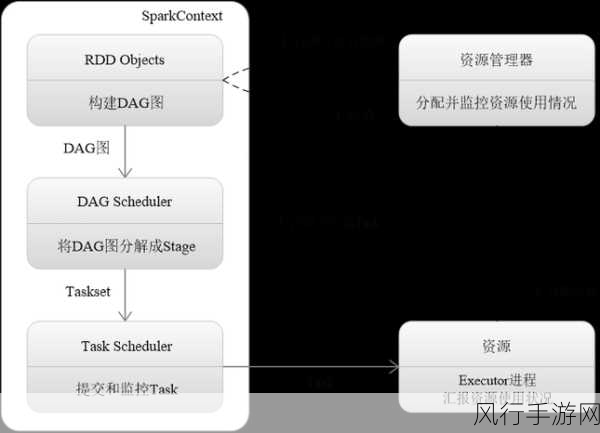
Spark 能够高效处理大规模数据,这得益于其卓越的分布式计算能力,传统的数据处理框架在面对海量数据时往往力不从心,而 Spark 凭借其出色的架构设计,可以将计算任务分配到多个节点上并行执行,大大缩短了数据处理的时间。
Spark 提供了丰富的 API 接口,使得开发者能够轻松地使用各种编程语言进行开发,无论是熟悉 Java 还是 Python 的开发者,都能在 Spark 中找到熟悉且易用的接口,从而快速上手并构建出复杂的数据处理应用。
其内存计算的特性也是一大亮点,通过将数据缓存在内存中,Spark 避免了频繁的磁盘 I/O 操作,极大地提高了数据访问和计算的速度,尤其是对于那些需要反复使用的数据,内存计算能够显著提升处理效率。
Spark 还具有良好的容错性,在分布式计算环境中,节点故障是不可避免的,Spark 能够自动检测和处理这些故障,确保计算任务不会因为个别节点的问题而失败,它会重新分配任务,并在其他健康的节点上继续执行,保证了整个计算过程的稳定性和可靠性。
Spark 支持多种数据源的接入,无论是关系型数据库、文件系统还是 NoSQL 数据库,都可以方便地与 Spark 进行集成,实现数据的统一处理和分析。
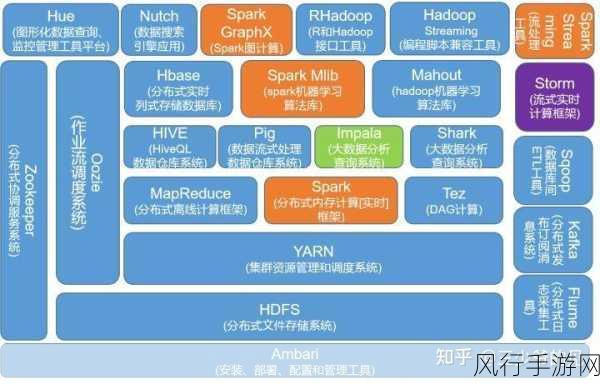
Spark 的生态系统非常丰富,除了核心的计算框架,还有一系列相关的组件和工具,如 Spark SQL 用于结构化数据处理,Spark Streaming 用于实时流数据处理,Spark MLlib 用于机器学习等,这些组件相互协作,为用户提供了全方位的数据处理和分析解决方案。
Spark 计算框架以其强大的功能、高效的性能、良好的容错性和丰富的生态系统,成为了大数据处理领域的首选之一,为企业和开发者在数据处理和分析方面带来了极大的便利和价值。