在当今数字化的时代,数据如同浩瀚的海洋,蕴藏着无尽的价值和信息,而大数据 Spark 则是我们在这片海洋中航行的强大工具,它以高效、灵活和强大的性能,为数据处理带来了革命性的变革。
Spark 之所以能够在数据处理领域大放异彩,得益于其独特的架构和设计理念,它摒弃了传统数据处理框架的诸多局限,采用了分布式计算的模式,将大规模的数据分割成多个小块,并在不同的节点上并行处理,大大提高了数据处理的速度和效率。
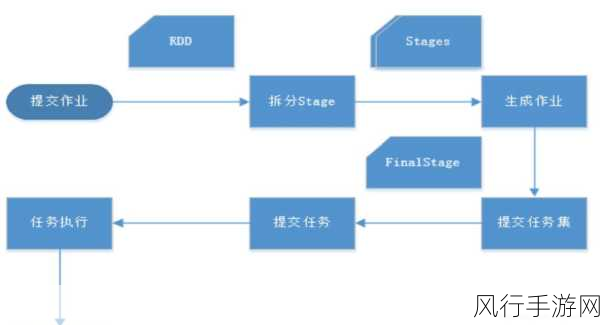
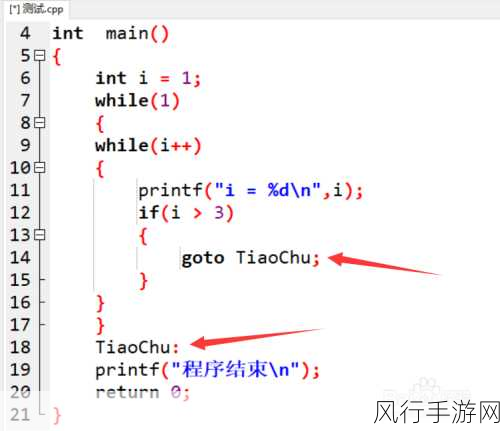
Spark 究竟是如何实现这神奇的数据处理流程的呢?
第一步,数据的读取与加载,Spark 支持从各种各样的数据源中读取数据,无论是结构化的数据库表,还是非结构化的文本文件、图片,甚至是实时的数据流,都能被 Spark 轻松纳入囊中,它通过强大的 API 和连接器,将这些数据源转化为可供处理的弹性分布式数据集(RDD)或者数据框(DataFrame),为后续的处理奠定了基础。

是数据的转换与操作,在这一阶段,Spark 提供了丰富多样的函数和操作符,让我们能够对数据进行筛选、过滤、聚合、排序等各种复杂的处理,这些操作不仅灵活易用,而且能够在分布式环境下高效执行,确保在处理大规模数据时依然能够保持出色的性能。
是数据的分组与聚合,通过分组操作,我们可以将具有相同特征的数据归为一组,并对每组数据进行聚合计算,例如求和、平均值、最大值、最小值等,这一过程能够帮助我们快速发现数据中的规律和趋势,提取出有价值的信息。
再之后,是数据的连接与合并,当我们需要将多个数据集进行关联和整合时,Spark 提供了高效的连接算法,能够快速准确地完成数据的合并,为我们呈现出一个完整、统一的数据视图。
是数据的输出与存储,经过一系列的处理和分析,我们需要将处理后的结果输出到合适的目标位置,Spark 支持将数据写入到各种存储系统,如数据库、文件系统、数据仓库等,确保数据能够被有效地保存和利用。
大数据 Spark 的数据处理流程就像是一场精心编排的舞蹈,每个步骤都紧密相连,协同工作,为我们展现出数据背后的精彩故事,通过深入理解和掌握 Spark 的数据处理流程,我们能够更好地挖掘数据的价值,为企业的决策提供有力的支持,推动业务的发展和创新,在未来,随着数据量的不断增长和数据处理需求的日益复杂,Spark 必将继续发挥其重要作用,引领着大数据处理的潮流。