Python 数据预处理,模型效果提升的关键密码
在当今数据驱动的时代,数据的质量和预处理对于构建有效模型至关重要,Python 作为一种强大而灵活的编程语言,在数据预处理方面展现出了卓越的能力,Python 数据预处理究竟能否提升模型效果呢?答案是肯定的。
数据预处理是模型构建过程中的重要环节,它就像是为高楼大厦打下坚实的地基,如果数据未经妥善处理,就如同使用劣质的材料建造房屋,即便后续的设计和施工再出色,也难以保证建筑的质量和稳定性,而 Python 提供了丰富的库和工具,使得数据预处理变得更加高效和便捷。
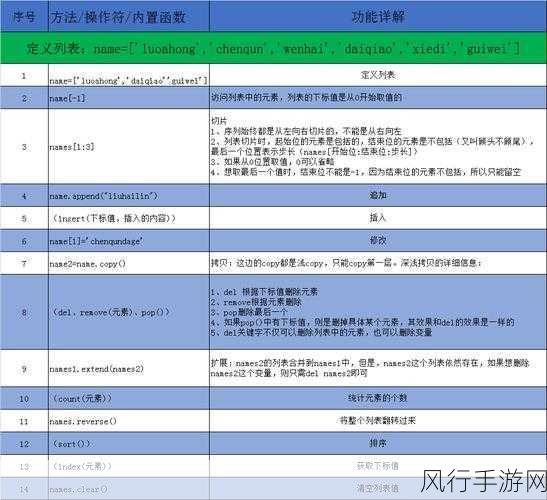
在数据收集阶段,往往会存在数据缺失、错误、重复等问题,Python 中的 Pandas 库可以轻松处理这些情况,通过数据清洗操作,如删除重复行、填充缺失值、纠正错误数据等,能够确保数据的准确性和完整性。
数据的标准化和归一化也是关键的一步,不同特征的量纲和取值范围可能差异巨大,这会对模型的训练和预测产生不良影响,Python 中的 sklearn 库提供了相应的函数,可以将数据进行标准化或归一化处理,使得各个特征在数值上具有可比性,从而提高模型的收敛速度和性能。

特征工程也是数据预处理中的重要内容,通过特征提取、特征选择和特征构建等操作,可以从原始数据中挖掘出更有价值的信息,Python 中的一些库,如 Featuretools ,能够帮助我们自动完成一些特征工程的任务,节省大量的时间和精力。
数据的划分也是不可忽视的环节,将数据集划分为训练集、验证集和测试集,能够更好地评估模型的性能和泛化能力,Python 中的 sklearn 库再次发挥作用,提供了方便的函数来实现数据的划分。
Python 数据预处理在提升模型效果方面发挥着不可或缺的作用,它能够为模型提供高质量、干净、有代表性的数据,从而提高模型的准确性、稳定性和泛化能力,在进行模型构建时,务必重视数据预处理这一环节,充分利用 Python 的强大功能,为模型的成功奠定坚实的基础。
Python 数据预处理是模型构建中的关键步骤,它就像一把神奇的钥匙,能够打开模型效果提升的大门,只有经过精心预处理的数据,才能让模型展现出其最佳性能,为解决各种实际问题提供有力的支持。