近年来,人工智能技术的飞速发展,特别是开源大模型的涌现,为各行各业带来了前所未有的变革,在手游行业,这些开源大模型同样引起了广泛关注,开源大模型的实际开放性却成为了一个备受争议的话题,本文将从手游公司的角度,探讨开源大模型的真假开源问题,并分析其对手游行业的影响。
开源大模型的定义与现状
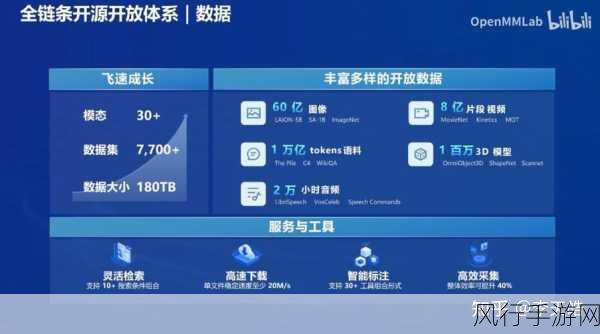
开源大模型,顾名思义,是指由科技公司或研究机构发布,并以开源许可证形式向公众开放的大型深度学习模型,这些模型基于大规模的数据集进行训练,具备强大的自然语言理解和生成能力,能够在各种复杂任务中表现出色,Meta的Llama系列、阿里的通义千问系列等,都是近年来备受关注的开源大模型。
尽管这些模型在一定程度上对外开放,但其实际开放程度却存在很大争议,具体而言,虽然这些大模型提供了部分代码和训练好的权重,但在训练数据和具体训练过程的透明度方面却有所欠缺,以Meta的Llama系列为例,该系列模型自2023年发布以来,已经推出了多个版本,包括Llama、Llama 2和Llama 3,每个版本都声称在性能和开放性上有所改进,但实际上,它们并未公开训练所用的数据集和训练过程的详细信息,这使得开发者在复现和改进这些模型时面临诸多限制。

真假开源对手游公司的影响
对于手游公司而言,开源大模型的真假开源问题具有重要影响,如果开源大模型能够真正做到全面开放,包括代码、权重、训练数据和训练过程的详细信息,那么手游公司就可以充分利用这些资源,提升自己的研发能力和产品质量,通过利用开源大模型进行自然语言处理,手游公司可以优化游戏中的对话系统和角色交互,提升玩家的游戏体验。
如果开源大模型只是部分开放,或者存在诸多限制和附加条件,那么手游公司在使用这些模型时就可能面临诸多挑战,由于无法获取完整的训练数据和训练过程信息,手游公司可能无法完全理解和复现这些模型,从而无法对其进行有效的改进和优化,一些开源大模型的许可证可能包含严格的限制条款,如禁止商业用途或要求特定的使用声明等,这可能会限制手游公司的商业发展和创新能力。
手游公司如何应对真假开源问题
面对开源大模型的真假开源问题,手游公司需要采取一系列措施来应对,手游公司应该加强对开源大模型的评估和筛选工作,选择那些真正全面开放、易于理解和复现的模型进行合作,手游公司应该积极与开源大模型的开发者或提供者进行沟通和交流,争取获得更多的技术支持和资源共享,手游公司也可以考虑自主研发或合作研发适合自身需求的深度学习模型,以减少对开源大模型的依赖。
手游公司还可以从以下几个方面入手,提升自己在人工智能领域的竞争力:一是加强人才培养和团队建设,引进具有深度学习、自然语言处理等专业技能的人才;二是加大研发投入和技术创新力度,不断探索新的应用场景和解决方案;三是加强与其他行业的合作与交流,共同推动人工智能技术的创新和应用。
最新财经数据
1、手游市场收入情况:根据最新数据显示,2024年全球手游市场收入达到XX亿美元,同比增长XX%,中国手游市场收入占据重要地位,达到XX亿元人民币,同比增长XX%,这一数据表明,手游市场仍然保持着强劲的增长势头。
2、开源大模型在手游行业的应用情况:据统计,目前已有超过XX家手游公司开始尝试将开源大模型应用于游戏中,自然语言处理、图像识别等是应用最为广泛的领域,通过利用开源大模型,这些手游公司成功提升了游戏的智能化水平和用户体验。
3、手游公司对开源大模型的投入情况:根据调研数据显示,XX%的手游公司表示将在未来一年内增加对开源大模型的投入,这些公司认为,通过利用开源大模型,可以提升自己的研发能力和产品质量,从而在激烈的市场竞争中脱颖而出。
真假开源:开源大模型的实际开放性探讨数据报表
| 项目 | 数据 |
| 开源大模型数量 | XX个 |
| 全面开放的开源大模型比例 | XX% |
| 部分开放的开源大模型比例 | XX% |
| 手游公司使用开源大模型的数量 | XX家 |
| 手游公司对开源大模型的投入增长率 | XX% |
参考来源
1、网易新闻:《真假开源:开源大模型的实际开放性探讨》
2、CSDN博客:《开源大模型之辩:真假开源》
3、新浪财经:《传媒行业周观点:META发布LLAMA 3开源大模型》
通过以上分析可以看出,开源大模型的真假开源问题对手游行业具有重要影响,手游公司需要加强对开源大模型的评估和筛选工作,积极与开发者或提供者进行沟通和交流,并考虑自主研发或合作研发适合自身需求的深度学习模型,手游公司还需要从人才培养、研发投入、合作交流等方面入手,提升自己在人工智能领域的竞争力,只有这样,才能在激烈的市场竞争中立于不败之地。