在 C 语言中,set 排序是一个备受关注的话题,set 作为一种数据结构,其排序性能对于程序的效率和运行结果有着重要的影响。
C 语言中的 set 通常是通过特定的算法和数据结构来实现排序功能的,在评估其性能时,需要考虑多个因素,数据量的大小是一个关键因素,当数据量较小时,set 排序的速度可能相对较快,因为处理少量数据的计算负担较小,随着数据量的不断增加,排序所需要的时间和资源也会相应增加。
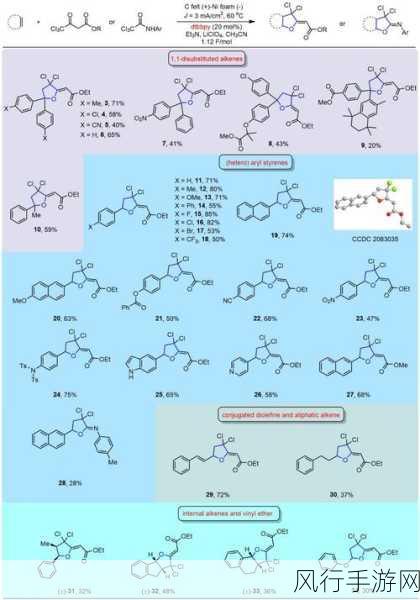
set 排序的性能还受到数据的分布特点的影响,如果数据的分布较为均匀,那么排序的效率可能会较高,但如果数据存在大量的重复或者异常值,可能会导致排序过程中的比较和交换操作增多,从而影响性能。
所使用的排序算法也对性能有着直接的关系,常见的排序算法如冒泡排序、快速排序、归并排序等,在不同的情况下表现各异,一些算法在特定的数据特征下能够发挥出较好的性能,而在其他情况下可能效果不佳。
为了更准确地评估 C 中 set 排序的性能,我们可以进行实际的测试和实验,通过编写代码,生成不同规模和特征的数据,并测量排序所花费的时间和资源消耗,从而得出有价值的结论。
C 中 set 排序的性能是一个复杂的问题,受到多种因素的综合影响,在实际应用中,需要根据具体的需求和场景,选择合适的数据结构和排序算法,以达到最优的性能效果。
