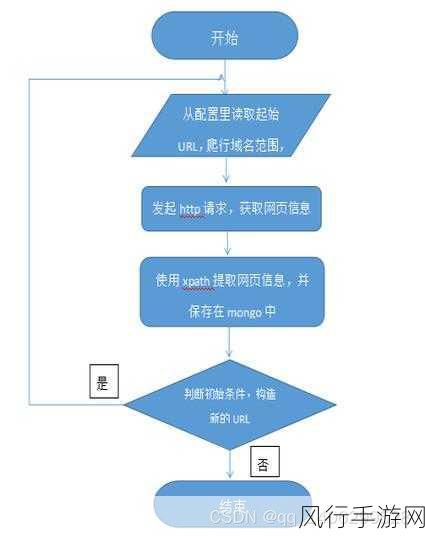
Python 爬虫框架在当今的数据获取领域中发挥着重要作用,要实现更高效的爬虫性能,需要我们深入理解和运用一系列的技术和策略。
性能提升的一个关键在于优化网络请求,通过合理设置请求头、采用合适的 HTTP 方法以及控制请求频率,可以有效避免被目标网站识别为恶意爬虫而被封禁,利用异步请求和并发处理技术,能够显著提高爬虫的效率,在短时间内获取大量数据。
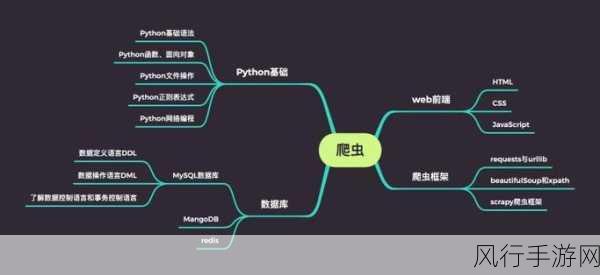
数据处理环节同样对性能有着重要影响,在爬取到数据后,需要迅速进行清洗、筛选和转换,采用高效的算法和数据结构,如哈希表、布隆过滤器等,可以快速过滤掉重复和无效的数据,减少后续处理的负担。
合理利用缓存机制也是提升性能的重要手段,对于经常访问且变化不大的页面,可以将其结果缓存起来,避免重复爬取,节省时间和资源,对爬虫框架的配置进行精细调整,根据实际需求设置线程数、连接池大小等参数,以达到最佳的性能平衡。
在存储方面,选择合适的数据库和存储格式也至关重要,对于大规模的数据,传统的关系型数据库可能无法满足性能要求,此时可以考虑使用非关系型数据库如 MongoDB 或者分布式存储系统。
要关注爬虫框架的稳定性和容错性,在网络不稳定或者遇到异常情况时,爬虫能够自动重试、恢复,并记录错误信息,以便后续排查和优化。
不断对爬虫进行性能测试和监测也是必不可少的,通过分析各项指标,如响应时间、吞吐量、资源利用率等,能够及时发现性能瓶颈,并针对性地进行优化。
提升 Python 爬虫框架的性能是一个综合性的任务,需要从多个方面入手,不断探索和实践,才能在合法合规的前提下,实现高效、稳定的数据获取。