探索 Spark Diff 在分布式数据处理中的神奇魔法
在当今数字化时代,数据处理成为了企业和组织面临的重要挑战之一,而 Spark 作为一款强大的大数据处理框架,其提供的 Spark Diff 功能在处理分布式数据方面有着独特的优势和方法。
Spark Diff 能够高效地处理分布式数据,这得益于其先进的算法和优化策略,它能够快速识别数据中的差异,并对这些差异进行准确的处理和分析,在实际应用中,Spark Diff 可以用于数据的同步、数据的变更检测以及数据的版本控制等多个场景。
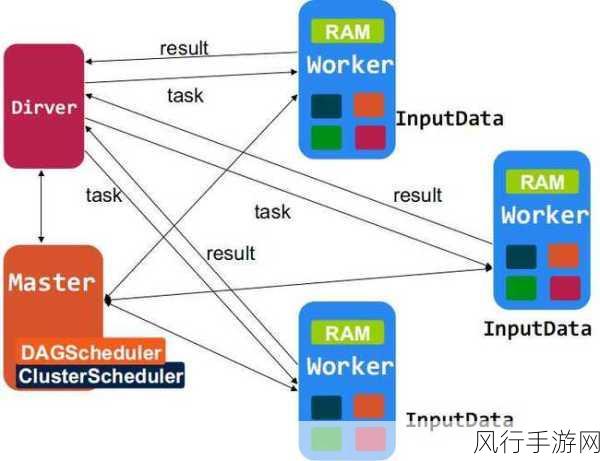
当我们深入研究 Spark Diff 处理分布式数据的过程时,会发现其背后有着一系列复杂而精妙的机制,比如说,它会将数据进行合理的分区,使得在分布式环境下的计算能够并行进行,从而大大提高了处理效率,它还会采用一些优化的比较算法,以减少计算量和资源消耗。
Spark Diff 在处理大规模分布式数据时,还充分考虑了数据的分布特点和网络传输的影响,通过巧妙地利用数据的局部性原理,减少了数据在网络中的传输量,降低了网络延迟对处理性能的影响。
为了更好地理解 Spark Diff 如何处理分布式数据,我们可以通过一个具体的案例来进行分析,假设我们有一个大型电商平台,每天都会产生海量的交易数据,这些数据分布在多个服务器上,我们需要检测每天数据的变化情况,以便及时发现异常和进行业务分析,使用 Spark Diff ,我们可以轻松地完成这个任务,将分布式的数据加载到 Spark 中,然后利用 Spark Diff 的功能进行差异计算,最终得到我们想要的结果。
在实际使用 Spark Diff 处理分布式数据时,还需要注意一些问题,数据的格式和结构要保持一致,否则可能会导致差异计算的错误,对于大规模数据的处理,还需要合理配置资源,以确保系统的稳定性和性能。
Spark Diff 为处理分布式数据提供了一种高效、可靠的解决方案,随着大数据技术的不断发展,相信 Spark Diff 在未来的数据处理领域中将会发挥更加重要的作用。