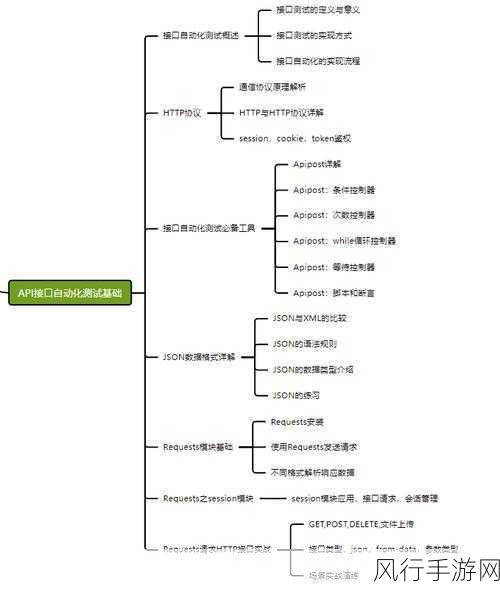
Hive 数据仓库在当今大数据时代扮演着至关重要的角色,它为企业和组织提供了一种高效、可靠的方式来处理海量数据,当面对大数据量时,Hive 凭借其独特的特性和强大的功能,展现出了卓越的处理能力。
Hive 能够处理大数据量,关键在于其分布式架构,它基于 Hadoop 生态系统,充分利用了分布式存储和计算的优势,通过将数据分布在多个节点上进行存储和处理,大大提高了数据处理的效率和可扩展性,这意味着即使数据量不断增长,Hive 也能够轻松应对,而不会出现性能瓶颈。
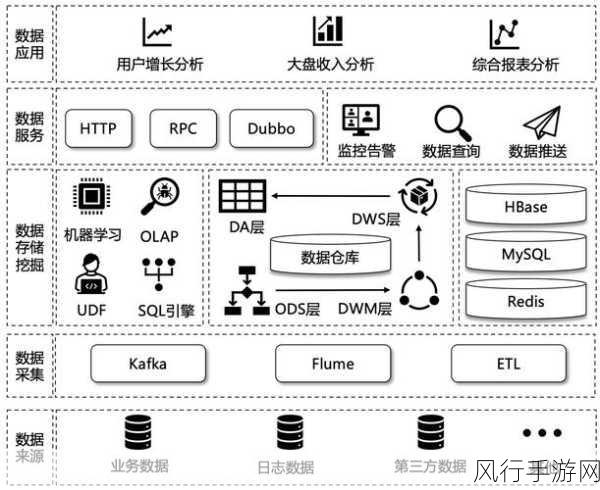
Hive 中的分区技术也是处理大数据量的重要手段之一,通过合理地对数据进行分区,可以将大规模的数据划分成较小的、更易于管理和处理的子集,这样在查询数据时,Hive 能够仅扫描相关分区,从而显著减少数据读取量,提高查询性能,按照时间、地域或者业务类别进行分区,可以快速定位和处理特定范围内的数据。
Hive 还支持数据压缩,在存储大数据量时,采用合适的压缩算法能够大幅减少数据占用的存储空间,同时降低数据传输和处理的开销,这不仅节省了硬件资源,还提高了数据处理的速度。
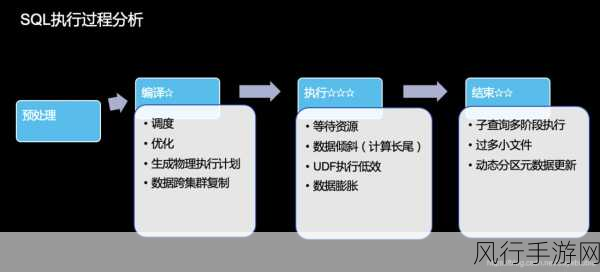
索引的运用也是 Hive 处理大数据量的有效策略,为经常用于查询和连接的列创建索引,可以加快数据的检索速度,但需要注意的是,过度创建索引可能会带来额外的维护成本和性能开销,因此需要根据实际业务需求进行权衡和优化。
Hive 的优化器在处理大数据量时发挥着重要作用,它能够根据查询语句的特点和数据的分布情况,自动选择最优的执行计划,对于复杂的连接操作,优化器会选择合适的连接算法和执行顺序,以确保高效地完成数据处理任务。
在实际应用中,合理配置 Hive 的参数也是至关重要的,包括内存设置、并行度调整等,都能够对 Hive 处理大数据量的性能产生显著影响。
Hive 数据仓库通过其分布式架构、分区技术、数据压缩、索引运用、优化器以及合理的参数配置等多种手段,为处理大数据量提供了强大而有效的解决方案,随着大数据技术的不断发展和应用需求的日益增长,Hive 将继续在数据处理领域发挥重要作用,帮助企业和组织从海量数据中挖掘出有价值的信息。