在当今数字化的时代,数据的获取和分析变得愈发重要,Python 爬虫作为一种强大的数据采集工具,备受关注,而其中一个常见的问题便是:Python 爬虫能否兼容不同的浏览器?
要回答这个问题,我们需要先了解 Python 爬虫的工作原理,Python 爬虫通过模拟浏览器的行为,向目标网站发送请求,并解析返回的网页内容来获取所需的数据,不同的浏览器在处理网页的方式上可能存在差异,这就给 Python 爬虫的兼容性带来了挑战。

不同的浏览器内核和渲染引擎会导致网页的显示和结构有所不同,Chrome 浏览器使用的 Blink 内核,Firefox 浏览器使用的 Gecko 内核,IE 浏览器使用的 Trident 内核等,这些内核在解析 HTML、CSS 和 JavaScript 等方面可能会有细微的差别,从而影响到 Python 爬虫获取数据的准确性和完整性。
浏览器的设置和插件也可能对 Python 爬虫产生影响,有些浏览器可能会启用反爬虫机制,例如检测频繁的请求、识别异常的请求模式等,而一些插件,如广告拦截插件,可能会改变网页的结构,导致 Python 爬虫无法正确解析页面。
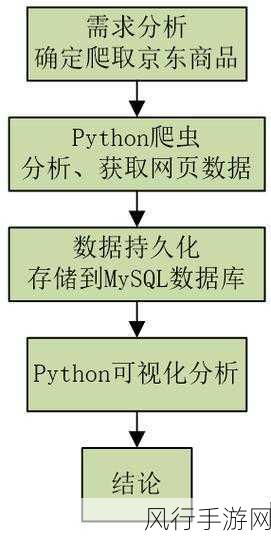
为了提高 Python 爬虫对不同浏览器的兼容性,开发者可以采取一些策略,一种常见的方法是使用多种模拟浏览器的库和工具,以适应不同的浏览器环境,Selenium 是一个强大的 Web 自动化测试工具,可以模拟多种主流浏览器的操作。
开发者还需要对目标网站进行充分的分析和研究,了解网站的反爬虫策略,遵循网站的使用规则,合理控制请求频率和请求参数,以避免被网站识别为爬虫并进行封禁。
对于网页内容的解析,应该采用灵活和通用的方法,不依赖于特定浏览器的解析方式,而是使用成熟的网页解析库,如 BeautifulSoup、lxml 等,它们能够处理各种不同结构的网页。
Python 爬虫在理论上可以努力实现对不同浏览器的兼容,但这需要开发者具备丰富的技术知识和经验,以及对目标网站的深入了解,只有在不断的实践和优化中,才能让 Python 爬虫在复杂的网络环境中更加稳定和高效地运行,为我们获取有价值的数据提供有力支持。
在未来,随着技术的不断发展和浏览器的更新换代,Python 爬虫与浏览器的兼容性问题也将不断变化和演进,持续的学习和创新是解决这一问题的关键,希望通过以上的探讨,能让您对 Python 爬虫与不同浏览器的兼容性有更清晰的认识。