在当今数据驱动的时代,深度学习模型的性能评估至关重要,PyTorch 和 PyG(PyTorch Geometric)作为强大的工具,为我们提供了丰富的手段来优化模型评估。
模型评估是衡量模型性能和效果的关键环节,它不仅能够帮助我们了解模型在现有数据上的表现,还能为进一步的改进和优化提供方向,对于 PyTorch 和 PyG 框架下的模型评估,我们需要综合考虑多个方面。
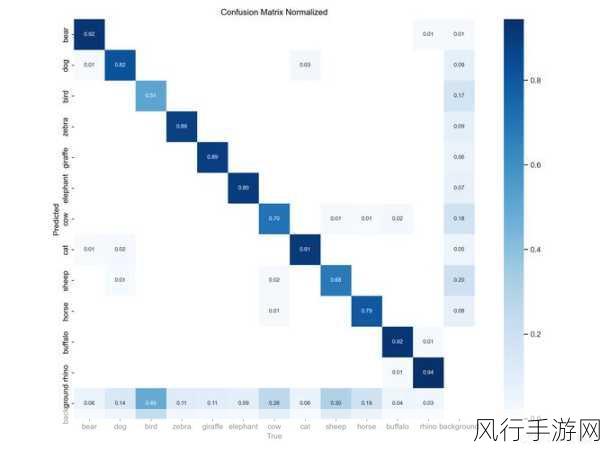
要优化模型评估,一个重要的方面是选择合适的评估指标,常见的指标如准确率、召回率、F1 值等在不同的任务中具有不同的意义和适用性,在二分类问题中,准确率可能是一个直观的指标,但在不平衡数据集上,召回率和 F1 值可能更能反映模型的真实性能。
数据的预处理和增强也是不可忽视的环节,合理的数据清洗、归一化、标准化等操作能够提升模型的稳定性和泛化能力,通过数据增强技术,如翻转、旋转、添加噪声等,可以增加数据的多样性,减少过拟合的风险。
模型的架构和超参数调整对评估结果有着显著影响,在 PyTorch 和 PyG 中,我们可以尝试不同的网络结构、层数、神经元数量等,以及调整学习率、正则化参数等超参数,这通常需要通过大量的实验和对比来找到最优的组合。
利用早停法(Early Stopping)可以避免模型过度训练,通过在验证集上监测模型的性能,当性能不再提升时提前停止训练,节省计算资源并防止过拟合。
在模型评估过程中,交叉验证也是一种常用的技术,它能够更全面地评估模型在不同数据子集上的表现,提高评估的可靠性和稳定性。
对于大规模数据和复杂模型,分布式训练和计算资源的合理利用能够加速评估过程,PyTorch 提供了相关的分布式训练接口,使得我们能够在多个计算节点上并行计算,提高效率。
模型的可视化和解释性也是优化评估的一部分,通过对模型的中间输出、特征重要性等进行可视化和分析,我们可以更好地理解模型的决策过程,发现潜在的问题和改进点。
优化 PyTorch 和 PyG 中的模型评估需要我们从多个角度入手,综合运用各种技术和方法,不断试验和改进,以获得更准确、可靠和有价值的评估结果,为模型的优化和应用提供有力支持。