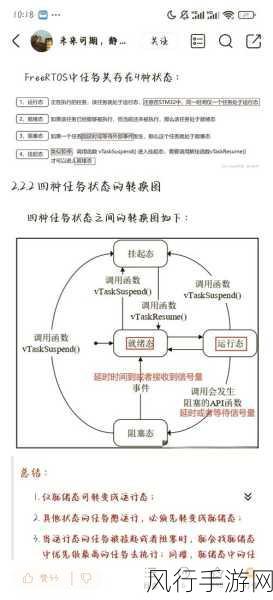
在当今数字化的时代,数据的获取和分析变得愈发重要,Python 爬虫作为一种强大的数据采集工具,在帮助我们获取所需信息的过程中发挥着关键作用,许多网站为了保护自身的数据和服务质量,纷纷设置了反爬机制,这给爬虫的工作带来了不小的挑战,特别是在使用 requests 库进行爬虫时,如何有效地处理反爬机制成为了一个关键问题。
要处理反爬机制,我们需要先对常见的反爬手段有清晰的认识,网站可能会通过检测请求的频率来判断是否为爬虫,如果短时间内发送过多的请求,就可能被封禁或者限制访问,一些网站还会通过检查请求头中的 User-Agent 等信息来识别爬虫。
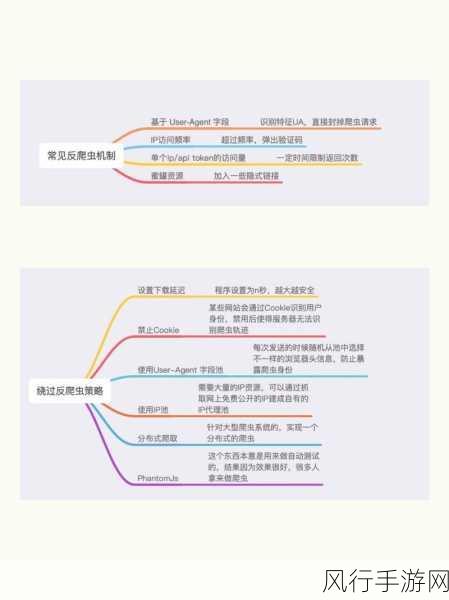
针对请求频率的限制,我们可以采用设置随机的请求间隔时间来模拟真实用户的访问行为,使用 Python 的随机数生成函数来设定每次请求之间的等待时间,这样就不会因为过于频繁的请求而被发现。
对于 User-Agent 的检测,我们可以从一些常见的浏览器中获取真实的 User-Agent 信息,并在每次请求时随机选择一个进行设置,这样可以让服务器认为我们的请求来自于正常的浏览器访问。

验证码也是常见的反爬手段之一,如果遇到需要输入验证码才能继续访问的情况,我们可以考虑使用第三方的验证码识别服务,或者通过手动输入的方式来解决。
还有一种情况是网站通过 IP 地址来限制访问,在这种情况下,我们可以使用代理 IP 来切换访问的 IP 地址,从而绕过限制。
在处理反爬机制的过程中,我们还需要注意遵守法律法规和网站的使用规则,不要进行非法或者恶意的爬虫行为,也要不断地学习和研究新的反爬技术,以便能够及时应对各种变化。
处理 Python 爬虫中 requests 遇到的反爬机制需要我们综合运用多种技术和策略,并且要保持耐心和细心,只有这样,我们才能在合法合规的前提下,顺利地获取到所需的数据。