在当今数字化时代,数据的一致性对于应用程序的可靠性和稳定性至关重要,当涉及到 Node.js 和 Redis 时,确保数据的一致性成为了开发者们需要重点关注和解决的问题。
Redis 作为一种高性能的内存数据存储系统,常被用于缓存、会话存储等场景,而 Node.js 则以其高效的异步非阻塞 I/O 模型在服务器端开发中广泛应用,在两者结合使用的过程中,由于各种因素的影响,可能会导致数据不一致的情况发生。
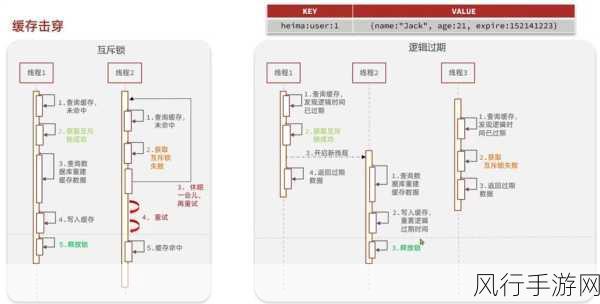
究竟有哪些方法可以保证 Node.js 和 Redis 之间的数据一致性呢?
一种常见的方法是采用事务机制,在 Redis 中,事务可以将多个命令打包成一个原子操作,要么全部执行成功,要么全部失败回滚,通过在 Node.js 中合理地组织和发送事务命令,可以有效地保证数据的一致性,当需要同时更新多个相关的数据项时,可以将这些更新操作放入一个 Redis 事务中执行,避免部分更新成功而部分失败的情况。
另一个重要的策略是设置合适的过期时间,对于一些临时或时效性较强的数据,可以为其在 Redis 中设置合理的过期时间,这样,即使在数据同步或更新过程中出现问题,过期的数据也会自动被清除,从而减少不一致数据的存在时间。
使用消息队列来协调 Node.js 和 Redis 的操作也是一种有效的方式,当 Node.js 对数据进行修改时,可以将相关的操作信息发送到消息队列中,Redis 则从队列中获取并执行相应的操作,确保数据的同步和一致性。
在实际开发中,还需要对数据的读写操作进行严格的权限控制和错误处理,对于关键的数据操作,要进行充分的验证和异常处理,以防止因错误操作导致的数据不一致。
保证 Node.js 和 Redis 之间的数据一致性是一个复杂但至关重要的任务,需要开发者综合运用多种技术和策略,根据具体的业务场景和需求,选择最合适的方法来确保数据的准确性和可靠性,只有这样,才能构建出高性能、稳定可靠的应用程序,为用户提供优质的服务体验。