HDFS(Hadoop 分布式文件系统)和 HBase(Hadoop 数据库)是大数据领域中两个重要的组件,它们的协同工作为处理海量数据提供了强大的支持。
HDFS 作为一种分布式文件存储系统,具备出色的可扩展性和容错性,能够存储大规模的数据,而 HBase 则是建立在 HDFS 之上的分布式数据库,它提供了对大规模数据的实时读写访问能力。

要理解它们的协同工作,需要先明确各自的特点和优势,HDFS 适合存储大量的静态数据,对于数据的批量处理和顺序读取表现出色,HBase 则更擅长处理随机读写操作,能够快速响应数据的实时查询和更新请求。
在实际应用中,HDFS 为 HBase 提供了可靠的数据存储基础,HBase 中的数据会以表的形式存储在 HDFS 中,HDFS 负责保障数据的持久性和可靠性,当 HBase 进行数据写入时,新的数据会先被写入到内存中的 MemStore 中,当 MemStore 达到一定大小或满足其他条件时,数据会被刷写到 HDFS 中形成持久化的存储文件。
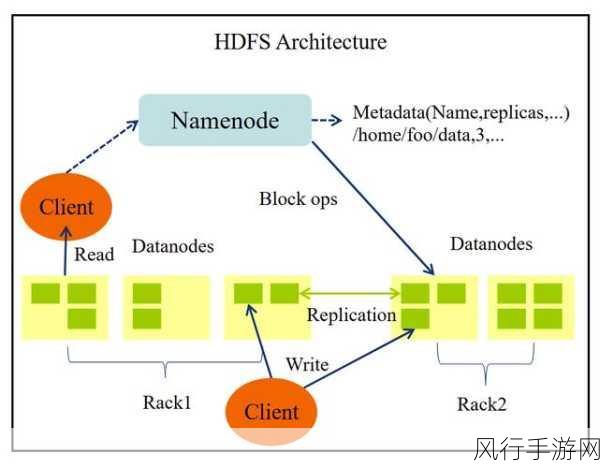
HBase 利用 HDFS 的分布式架构,实现了数据的自动分区和负载均衡,它可以根据数据的分布情况,将数据均匀地分布在不同的节点上,从而提高数据的访问效率和系统的整体性能。
HDFS 的副本机制也为 HBase 数据的可靠性提供了保障,HDFS 会自动为数据创建多个副本,并将它们存储在不同的节点上,这样即使某个节点出现故障,也能够从其他副本中获取数据,确保 HBase 服务的连续性和数据的可用性。
为了实现更高效的协同工作,还需要对 HDFS 和 HBase 进行合理的配置和优化,调整 HDFS 的块大小、副本数量,以及 HBase 的内存分配、缓存设置等,都能够根据具体的业务需求和数据特点来提升系统的性能。
HDFS 和 HBase 的协同工作是大数据处理中的一个关键环节,通过充分发挥它们各自的优势,能够构建出高效、可靠、可扩展的大数据处理系统,为企业和组织处理海量数据、挖掘数据价值提供有力的支持。