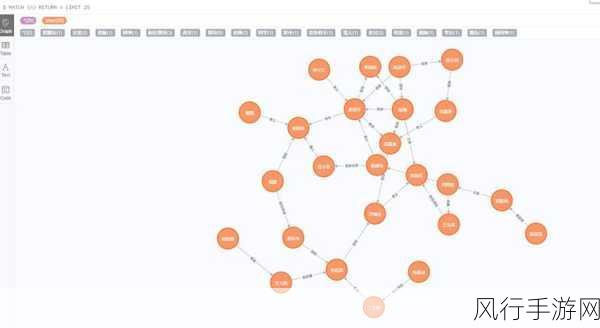
在当今数字化的时代,自然语言处理技术正以前所未有的速度发展和应用,随着其广泛应用,隐私保护问题也日益凸显。
自然语言处理技术在众多领域展现出强大的能力,比如智能客服、文本自动生成、情感分析等,但这种技术的运用并非毫无风险,当我们输入大量的文本数据以供模型学习和分析时,个人的隐私信息可能在不知不觉中被暴露。
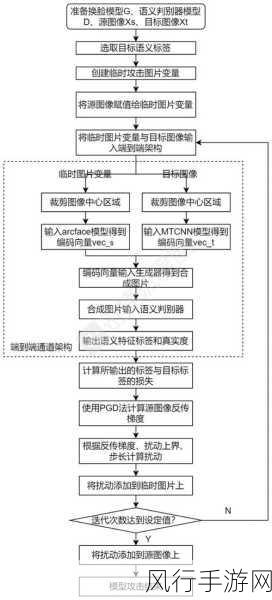
隐私保护在自然语言处理技术中的重要性不言而喻,如果用户的隐私得不到保障,他们可能会对使用相关技术产生顾虑,从而阻碍技术的进一步推广和应用,一旦隐私泄露,可能会给用户带来诸多不良后果,如身份盗窃、欺诈风险等。
如何在利用自然语言处理技术的同时保护好隐私呢?技术开发者应当采用先进的加密算法对数据进行处理,通过加密,即使数据在传输和存储过程中被获取,也难以被解读和理解,建立严格的数据访问控制机制至关重要,只有经过授权的人员,在特定的条件下,才能接触和处理相关数据。

在数据收集阶段,应当明确告知用户数据的用途和收集范围,并获得用户的明确同意,这不仅是对用户权利的尊重,也是建立良好用户信任的基础。
技术创新也是解决隐私保护问题的有效途径,开发联邦学习等技术,使得模型可以在不共享原始数据的情况下进行训练和优化。
自然语言处理技术为我们的生活带来了诸多便利,但我们不能忽视其可能带来的隐私风险,只有通过多方面的努力,包括技术手段、制度规范和用户意识的提升,才能实现技术发展与隐私保护的平衡,让自然语言处理技术更好地服务于人类社会。
保护隐私是自然语言处理技术持续健康发展的必要条件,我们每个人都应关注并积极参与其中,共同构建一个安全、可靠的数字环境。