Python 数据清洗作为数据分析和处理领域的重要环节,一直备受关注,它究竟能否应对大规模数据的挑战呢?
要回答这个问题,我们首先需要了解什么是数据清洗以及 Python 在其中的作用,数据清洗,就是对原始数据进行处理,去除噪声、纠正错误、填补缺失值等,以确保数据的质量和可用性,而 Python 凭借其丰富的库和强大的功能,为数据清洗提供了高效的工具和方法。

在大规模数据处理方面,Python 具有一些显著的优势,它的内存管理机制相对灵活,可以通过分块读取和处理数据的方式,有效地应对数据量过大导致内存不足的问题,像 Pandas 这样的库提供了高效的数据结构和操作方法,能够快速地对大规模数据进行筛选、转换和整合。
Python 数据清洗在处理大规模数据时也并非毫无挑战,性能可能是一个关键的制约因素,尽管 Python 有很多优化的方法和技巧,但在处理极其庞大的数据量时,可能需要更专业的分布式计算框架,如 Spark 等,来提高处理速度和效率。
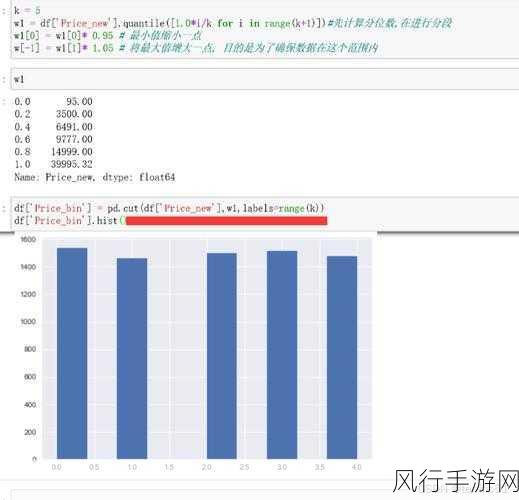
数据的复杂性也会给 Python 数据清洗带来困难,大规模数据往往具有多样的格式、复杂的结构和不一致的标准,这就要求数据清洗的代码具有高度的灵活性和可扩展性,以适应各种复杂的情况。
但这并不意味着 Python 不能处理大规模数据的清洗工作,通过合理的算法设计、优化代码、利用多核计算和并行处理技术,以及结合其他相关的工具和框架,Python 完全有能力应对大规模数据清洗的任务。
Python 数据清洗在大规模数据处理中具有很大的潜力和可能性,但要充分发挥其优势,需要我们深入理解数据特点,熟练掌握相关技术,并根据具体的应用场景进行合理的选择和优化,只要运用得当,Python 数据清洗能够为我们在大规模数据处理中提供有力的支持,帮助我们从海量数据中提取有价值的信息。