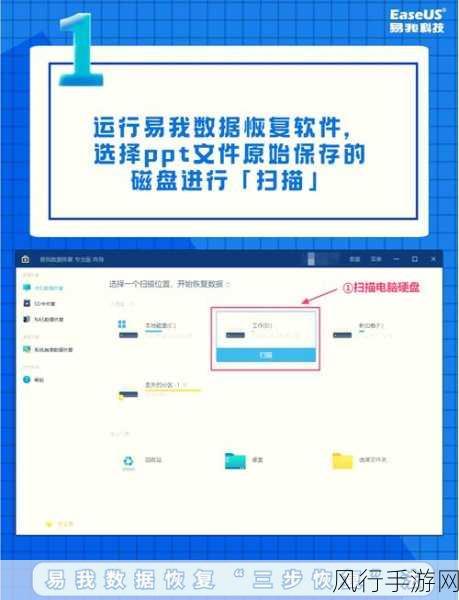
Redis 作为一款高性能的内存数据库,在众多应用场景中发挥着重要作用,而 Redis Set 数据结构在实际使用中,如何保证数据的一致性是一个至关重要的问题。
Redis Set 是一种无序且不允许重复元素的数据结构,在实现数据一致性方面,它采用了多种机制和策略。
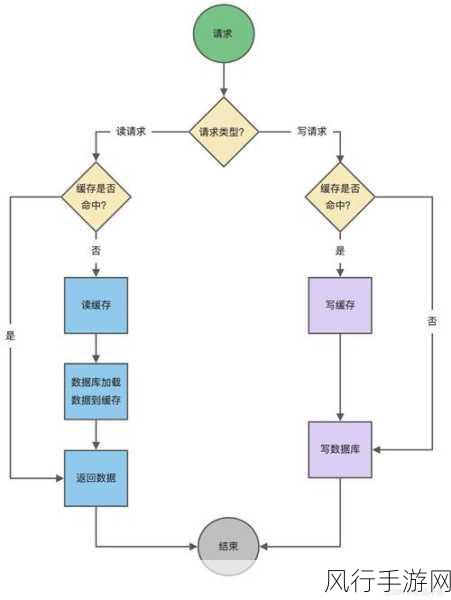
其一,Redis 本身具有事务机制,通过 MULTI、EXEC 等命令,可以将一系列操作包裹在一个事务中执行,在事务执行期间,要么所有操作都成功,要么所有操作都失败,从而保证了数据的一致性,当我们在对 Redis Set 进行添加、删除元素等操作时,如果将这些操作放入一个事务中,就能够避免部分操作成功而部分操作失败的情况。
其二,Redis 提供了持久化功能,AOF(Append Only File)和 RDB(Redis Database)两种持久化方式能够在服务器故障或重启时,将数据恢复到之前的状态,确保数据的一致性,对于 Redis Set 中的数据,持久化功能能够有效地防止数据丢失或不一致。
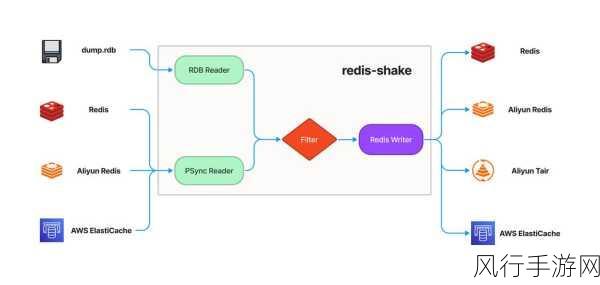
Redis 还采用了主从复制机制,在一个 Redis 集群中,存在主节点和从节点,主节点负责处理写操作,并将数据同步到从节点,这样,即使主节点出现故障,从节点也能够迅速接替工作,保证服务的连续性和数据的一致性。
在实际应用中,为了更好地保证 Redis Set 的数据一致性,还需要开发者在使用时遵循一些最佳实践,合理设计数据结构和操作逻辑,避免并发冲突;在进行重要操作之前,做好数据备份等。
Redis Set 保证数据一致性是通过多种技术手段的综合运用,同时也需要开发者在使用过程中谨慎处理,才能充分发挥其优势,为应用提供稳定可靠的数据服务。