当我们涉足 Python 数据分析领域时,面临的首要问题往往是如何挑选适合自己的工具,这并非是一个简单的任务,因为市场上有众多的选择,每种工具都有其独特的特点和优势。
不同的数据分析工具在功能、性能、易用性等方面存在差异,Pandas 是 Python 中用于数据处理和分析的核心库,它提供了丰富的数据结构和函数,能够轻松地处理各种数据格式,而 NumPy 则专注于数值计算,为高效的数组操作提供了强大的支持。

对于初学者来说,选择工具时应重点考虑易用性和学习资源的丰富程度,像 Jupyter Notebook 这样的交互式开发环境,能够让初学者迅速上手,实时看到代码的运行结果,有助于理解和调试代码。
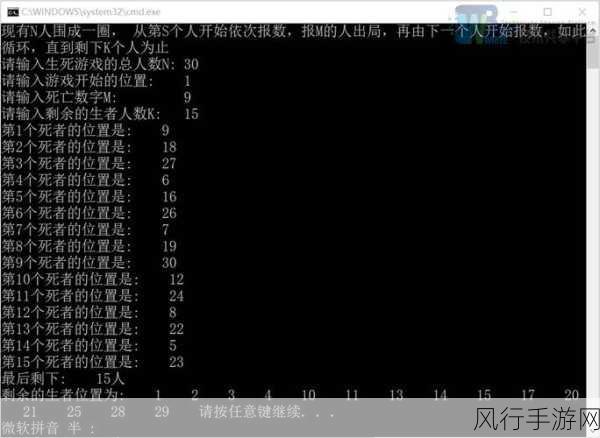
如果你的数据量较大,Dask 可能是一个不错的选择,它能够处理大规模的数据,提供了并行计算的能力,大大提高了数据处理的效率。
而对于需要进行复杂的机器学习和数据挖掘任务的用户,Scikit-learn 则是不可或缺的工具,它涵盖了各种常见的机器学习算法和模型评估指标,为数据分析和预测提供了有力的支持。
Matplotlib 和 Seaborn 是用于数据可视化的重要工具,它们能够将复杂的数据以直观、清晰的图表形式呈现出来,帮助我们更好地理解数据的特征和趋势。
在挑选 Python 数据分析工具时,要结合自身的需求、技术水平以及数据特点等多方面因素进行综合考虑,只有这样,才能找到最适合自己的工具,从而在数据分析的道路上更加得心应手,挖掘出数据背后的有价值信息。