Kafka 作为一种强大的分布式消息队列系统,在大数据处理和实时数据传输中发挥着重要作用,在实际应用中,可能会遇到 Kafka 消费延迟的问题,这无疑会影响整个系统的性能和效率,让我们深入探讨一些有效的优化措施,以解决这一棘手的难题。
要解决 Kafka 消费延迟问题,需要从多个方面入手,合理配置消费者参数是关键的一步,调整 fetch.min.bytes 和 fetch.max.wait.ms 这两个参数,fetch.min.bytes 决定了每次拉取数据的最小字节数,将其设置得过大可能导致等待时间过长,过小则可能导致频繁拉取,增加网络开销,fetch.max.wait.ms 则控制了在数据量不足 fetch.min.bytes 时的最大等待时间,设置不当也会影响消费的及时性。
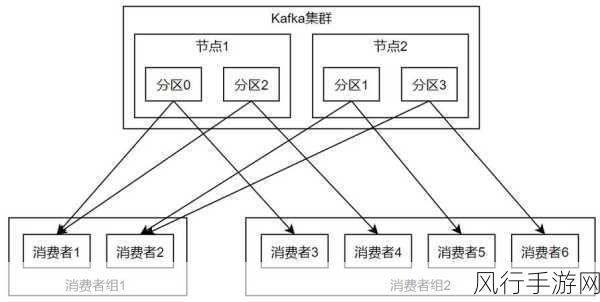
优化消费者的线程模型也不容小觑,如果消费逻辑较为复杂,单线程处理可能无法及时处理消息,导致延迟,可以考虑采用多线程并发处理的方式,但要注意线程数量的合理设置,避免过多线程造成资源竞争和上下文切换的开销。
还需要关注 Kafka 集群的性能和配置,确保 Broker 有足够的资源,如内存、CPU 和网络带宽等,合理设置分区数量和副本因子,既能保证数据的可靠性,又能提高消费的效率。
监控和告警机制也是必不可少的,通过实时监控消费延迟指标,及时发现问题,并在延迟超过阈值时发出告警,以便能够迅速采取措施进行调整和优化。
解决 Kafka 消费延迟问题需要综合考虑多个因素,并根据实际的业务场景和系统环境进行针对性的优化,只有不断地探索和实践,才能确保 Kafka 系统在处理数据时保持高效和稳定。