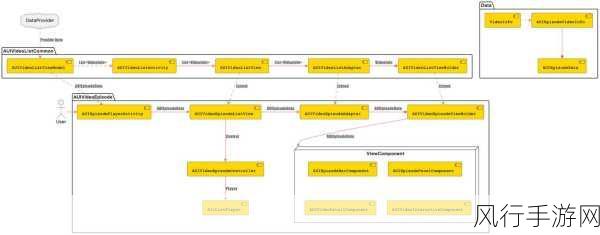
在当今数字化的时代,数据成为了无比宝贵的资源,而 Python 爬虫作为一种强大的工具,能够帮助我们从互联网的海量信息中获取所需的数据。
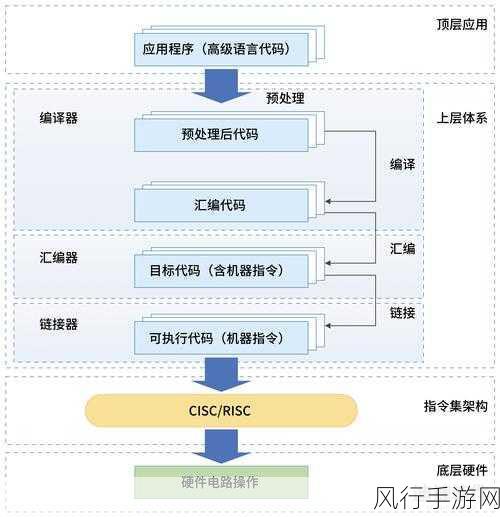
Python 爬虫的工作原理其实并不复杂,它就像是一个智能的采集者,通过模拟浏览器的行为,向目标网站发送请求,并接收和解析返回的页面内容,在这个过程中,需要运用到多种 Python 库和技术,比如requests 库用于发送请求,BeautifulSoup 或lxml 库用于解析页面。

要实现 Python 爬虫获取数据,第一步需要明确目标网站和要获取的数据类型,是要抓取网页中的文本内容,还是图片、链接等元素?这决定了后续的爬虫策略和代码编写方式。
需要分析目标网站的结构和页面规律,了解网页的 HTML 结构、页面的链接模式以及可能存在的反爬虫机制,这对于编写高效且稳定的爬虫至关重要。
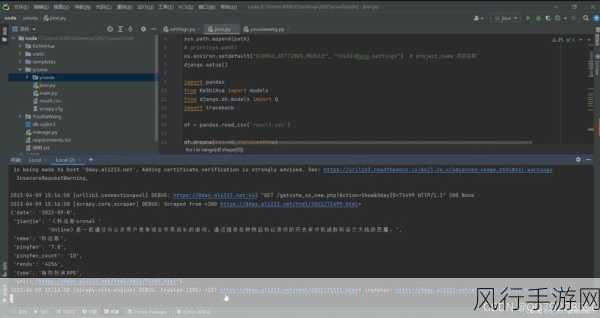
在发送请求时,要注意设置合适的请求头,模拟真实的浏览器访问,以降低被网站识别为爬虫而被封禁的风险,还要处理好请求的频率,避免对目标网站造成过大的负担。
获取到页面内容后,就轮到解析环节了,通过选择合适的解析库,提取出所需的数据,这可能需要一些正则表达式的知识,或者利用库提供的便捷方法来精准定位和提取数据。
使用 Python 爬虫获取数据并非毫无限制,许多网站都有其使用条款和服务协议,明确禁止未经授权的爬虫行为,在进行爬虫操作时,务必遵守法律法规和道德规范,尊重网站的权益。
Python 爬虫是获取数据的有力手段,但需要谨慎使用,合理规划,才能在不违反规则的前提下,充分发挥其优势,为我们的数据分析和应用提供有价值的支持。