在当今数字化时代,数据处理成为了企业和组织的核心任务之一,HBase 作为一种分布式数据库,在处理大规模数据时具有显著的优势,在使用 HBase 的 Get 操作时,数据倾斜问题可能会给系统性能带来严重的影响,如何避免这一棘手的问题呢?
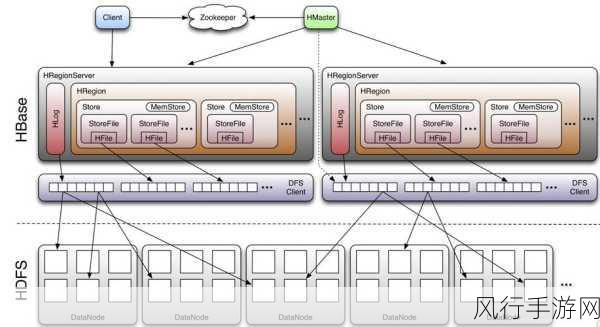
HBase 中的数据倾斜通常是由于数据分布不均匀导致的,某些 Region 承载了过多的数据请求,而其他 Region 则相对闲置,这就造成了系统资源的不均衡利用,进而影响整体性能。
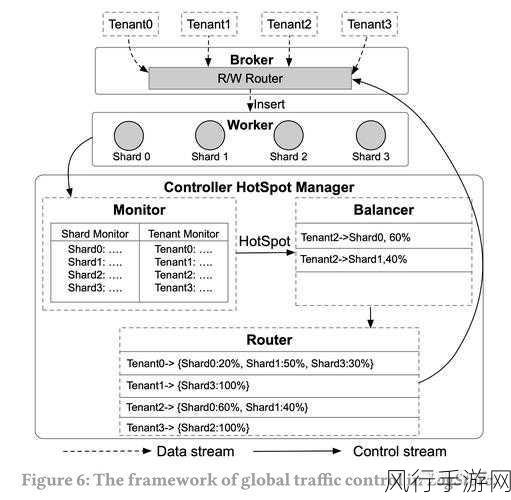
要解决 HBase Get 操作中的数据倾斜问题,关键在于优化数据的分布和访问模式,一种有效的方法是在数据写入阶段就进行合理的规划,确保数据在写入时能够尽可能均匀地分布到各个 Region 中,避免出现某些 Region 过度集中的情况,这需要对数据的特征和业务需求有深入的理解,以便制定合适的数据分区策略。
合理设置预分区也是一个重要的手段,通过预先确定好分区的边界,可以有效地控制数据的分布,减少数据倾斜的可能性,在进行预分区时,要充分考虑数据的增长趋势和访问模式,以确保分区的合理性和有效性。
优化查询语句也是不可忽视的一环,仔细检查和优化 Get 操作的查询条件,避免不必要的全表扫描或范围查询过大的情况,精确的查询条件能够更有针对性地获取所需数据,减轻对特定 Region 的压力。
还可以考虑使用缓存机制,对于经常访问的数据,可以将其缓存起来,以减少对 HBase 的直接访问,从而降低数据倾斜带来的影响。
避免 HBase Get 操作中的数据倾斜需要综合考虑多个方面,从数据写入、分区设置、查询优化到缓存利用等,只有通过精心的设计和持续的优化,才能确保 HBase 在处理数据时保持高效稳定的性能,为业务的发展提供有力的支持。