在当今数字化的时代,数据成为了宝贵的资源,而 Python 框架 Django 以其强大的功能和灵活性,在爬虫开发中备受青睐,当我们运用 Django 爬虫获取到大量数据后,如何进行有效的数据存储就成为了关键问题。
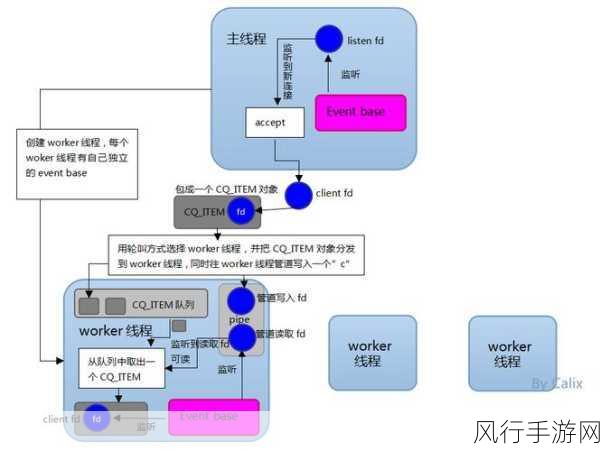
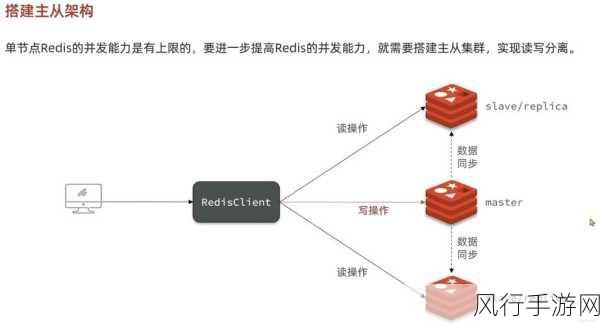
Django 提供了多种数据存储方式,每种方式都有其特点和适用场景,关系型数据库如 MySQL、PostgreSQL 是常见的选择,利用 Django 的 ORM(Object Relational Mapping,对象关系映射)机制,我们可以将爬取到的数据轻松地映射到数据库表中。
在进行数据存储之前,我们需要对爬取到的数据进行预处理和清洗,这可能包括去除重复数据、转换数据格式、处理异常值等操作,以确保数据的质量和一致性。
要根据数据的特点和需求设计合适的数据库表结构,合理的表结构能够提高数据存储和查询的效率,如果数据具有层次关系,可以考虑使用外键来建立关联;对于经常需要查询和统计的字段,可以添加适当的索引。
在 Django 项目中配置数据库连接信息,使其能够与选定的数据库进行通信,通过编写数据模型类,定义字段和相关的约束条件,Django 会自动为我们生成相应的数据库表。
在存储数据时,使用 Django 的数据保存方法将处理好的数据对象保存到数据库中,要注意处理可能出现的并发访问和数据一致性问题,确保数据的完整性和准确性。
除了关系型数据库,非关系型数据库如 MongoDB 也可以用于 Django 爬虫的数据存储,对于一些结构灵活、数据量较大且对查询性能要求较高的场景,非关系型数据库能够发挥其优势。
选择合适的数据存储方式,并进行精心的设计和处理,是确保 Django 爬虫获取到的数据能够得到有效利用和管理的重要环节,通过不断的实践和优化,我们能够更好地驾驭 Django 爬虫的数据存储,为数据分析和应用提供坚实的基础。