在当今数字化时代,数据库技术的发展日新月异,其中分布式事务处理成为了众多开发者面临的重要挑战之一,Swoole 作为一款高性能的异步网络通信引擎,在处理数据库中的分布式事务时有着独特的方式和策略。
要理解 Swoole 数据库如何处理分布式事务,我们需要先明确分布式事务的概念,分布式事务是指涉及多个节点或系统的事务操作,这些操作需要保证数据的一致性和完整性,与传统的单机事务不同,分布式事务面临着网络延迟、节点故障等诸多复杂情况。
Swoole 在处理分布式事务时,充分利用了其异步非阻塞的特性,通过异步的方式,可以并发地处理多个事务请求,提高了系统的并发处理能力,Swoole 还采用了一些优化策略来减少事务处理过程中的锁竞争,它可能会使用乐观锁或者分段锁的方式,来降低锁的粒度,从而提高事务处理的效率。
在数据一致性方面,Swoole 通常会借助一些分布式一致性算法,如 Paxos 或 Raft 算法,这些算法能够确保在多个节点之间的数据一致性,即使在部分节点出现故障的情况下,也能保证事务的正确执行。
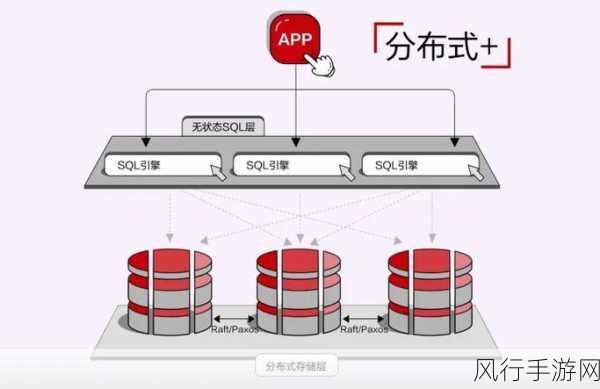
Swoole 还会注重事务的隔离级别,不同的隔离级别在保证数据一致性的同时,对系统性能的影响也有所不同,开发者需要根据具体的业务场景,合理选择合适的隔离级别,以达到性能和数据一致性的平衡。
为了更好地处理分布式事务,Swoole 还会结合数据库的特性进行优化,对于一些支持事务日志的数据库,Swoole 可以利用这些日志来进行事务的恢复和重演,从而提高事务处理的可靠性。
在实际应用中,使用 Swoole 处理分布式事务需要开发者具备扎实的技术功底和对分布式系统的深入理解,还需要对业务需求进行充分的分析,以便选择最合适的技术方案和策略。
Swoole 为处理数据库中的分布式事务提供了强大的支持和灵活的解决方案,但要充分发挥其优势,需要开发者不断探索和实践,结合具体的业务场景,打造出高效、可靠的分布式事务处理系统。