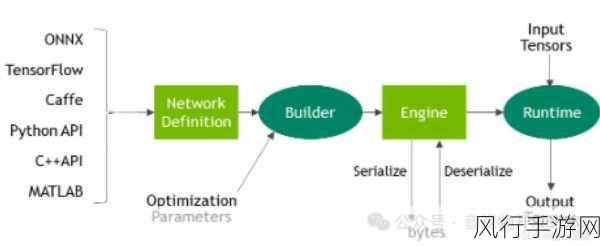
HBase 和 MLlib 作为大数据处理领域中的重要技术,它们在处理实时数据方面的表现备受关注。
HBase 是一个分布式、面向列的数据库,具有高可靠性、高性能和可扩展性,它适用于海量数据的存储和随机访问,能够在大规模数据场景下提供快速的数据读写操作,而 MLlib 则是 Spark 中的机器学习库,为数据挖掘和机器学习任务提供了丰富的算法和工具。
HBase 和 MLlib 能否处理实时数据呢?要回答这个问题,我们需要深入了解它们的特性和工作原理。
HBase 在实时数据处理中具有一定的优势,其分布式架构使得数据可以在多个节点上并行处理,从而提高数据的写入和读取速度,HBase 支持实时的数据插入和更新,能够及时反映数据的变化。
HBase 也存在一些局限性,它在复杂的查询和分析操作方面可能不如传统的关系型数据库那样灵活和高效,对于一些需要进行多表关联和复杂聚合计算的实时业务场景,HBase 可能无法完全满足需求。
MLlib 本身并不是直接用于实时数据处理的工具,但它可以与其他实时数据处理框架结合使用,以实现对实时数据的分析和挖掘,通过将实时数据流入 Spark 中,并利用 MLlib 中的算法进行模型训练和预测,可以为实时决策提供支持。
但需要注意的是,将 HBase 和 MLlib 应用于实时数据处理时,还需要考虑系统的资源配置、数据的预处理、模型的选择和优化等多个方面,只有在合理的设计和优化下,才能充分发挥它们在实时数据处理中的潜力。
技术的不断发展也为实时数据处理带来了新的可能性,我们或许可以期待 HBase 和 MLlib 在实时数据处理领域有更出色的表现和创新的应用。
HBase 和 MLlib 在处理实时数据方面具有一定的能力和潜力,但需要根据具体的业务需求和场景进行合理的选择和应用,并通过不断的优化和创新来满足日益复杂的实时数据处理要求。