在当今数字化时代,数据已成为企业和组织的重要资产,原始数据往往存在各种问题,如缺失值、错误数据、重复记录等,这就需要进行数据清洗来确保数据的质量和可用性,SQL on Hadoop 作为一种强大的技术,为数据清洗提供了高效且便捷的解决方案。
数据清洗是数据处理过程中的关键环节,它能够显著提升数据分析和决策的准确性,SQL on Hadoop 之所以在数据清洗中表现出色,得益于其强大的计算能力和灵活的查询语言。
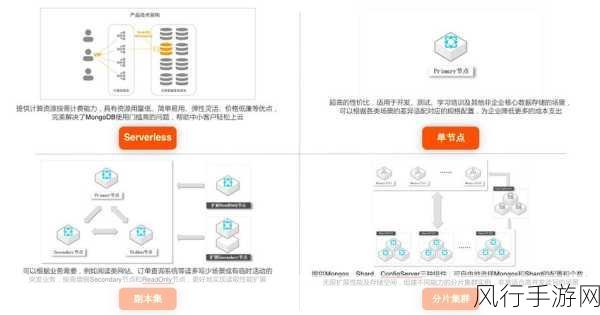
与传统的数据清洗方法相比,SQL on Hadoop 具有诸多优势,其一,它能够处理大规模的数据,无论是几百兆还是数 TB 的数据量,都能轻松应对,其二,它支持多种数据格式,包括结构化数据、半结构化数据和非结构化数据,使得数据的接入和处理更加灵活多样。
在进行 SQL on Hadoop 数据清洗时,需要遵循一定的步骤和策略,首先要明确清洗的目标和规则,例如确定哪些数据是无效的,哪些字段需要进行格式转换等,通过编写合适的 SQL 语句来实现这些清洗操作,使用WHERE 子句来筛选出符合条件的数据,使用UPDATE 语句来修改数据的值。

为了更好地进行数据清洗,还需要掌握一些常见的技巧和方法,利用临时表来存储中间结果,以便进行复杂的计算和处理,要注意数据的一致性和完整性,避免在清洗过程中引入新的错误。
在实际应用中,还需要考虑性能优化的问题,通过合理设置分区、建立索引等方式,可以提高数据清洗的效率,减少处理时间。
SQL on Hadoop 数据清洗是一项具有重要意义和实用价值的技术,它能够帮助我们从海量的数据中提取出有价值、准确和可靠的信息,为企业的发展和决策提供有力支持,随着技术的不断进步和应用场景的拓展,相信 SQL on Hadoop 在数据清洗领域将发挥更加重要的作用。