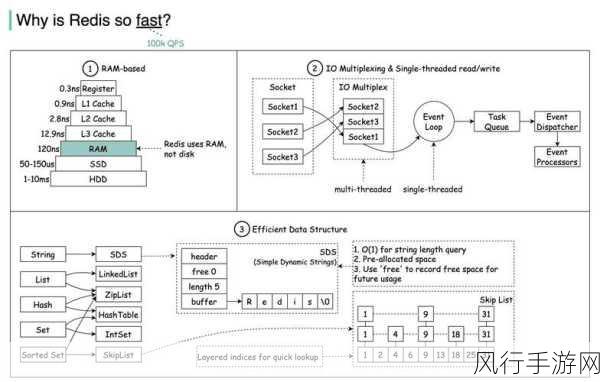
数据在当今数字化时代的重要性不言而喻,高质量的数据是做出准确分析和明智决策的基础,而 Python 作为一种强大且灵活的编程语言,在数据清洗方面发挥着重要作用,能够有效地提高数据质量。
在数据处理的流程中,数据清洗占据着关键的位置,脏数据、缺失值、异常值等问题常常困扰着数据分析师和研究人员,Python 提供了丰富的库和工具,让我们能够轻松应对这些挑战。
对于缺失值的处理,我们可以使用pandas 库中的fillna() 方法,这个方法允许我们根据不同的策略来填充缺失值,比如使用均值、中位数或者特定的固定值,通过合理地选择填充策略,能够在一定程度上减少缺失值对后续分析的影响。
再来看异常值的处理,异常值可能是由于数据录入错误或者真实的极端情况导致的,Python 中的统计函数和可视化工具可以帮助我们发现异常值,通过绘制数据的箱线图或者直方图,能够直观地观察到数据的分布情况,从而确定异常值的范围,一旦确定了异常值,我们可以选择删除或者修正它们。

数据的重复也是一个常见的问题,Python 中的drop_duplicates() 方法可以快速去除重复的数据行,确保数据的唯一性和准确性。
在数据类型的转换方面,Python 同样表现出色,数据可能以不恰当的类型存储,比如数值型数据被存储为字符串,通过pandas 的astype() 方法,我们可以将数据类型进行转换,以便进行后续的数学运算和分析。
除了上述的基本操作,数据清洗还需要考虑数据的一致性和准确性,检查数据的取值范围是否合理,确保数据符合业务逻辑和实际情况。
Python 为数据清洗提供了强大的支持,通过灵活运用各种库和方法,我们能够有效地提高数据质量,为后续的数据分析和挖掘打下坚实的基础,只有拥有高质量的数据,我们才能从数据中获取有价值的信息,做出更准确的决策,推动业务的发展和创新。