Kafka 作为一款高性能的分布式消息队列系统,在数据处理和消息传递领域发挥着重要作用,而对于 Kafka 中的 ConsumerRecord 是否能够进行持久化,这是一个值得深入探讨的问题。
要理解 ConsumerRecord 的持久化,我们需要先明确 ConsumerRecord 本身的概念和作用,ConsumerRecord 是 Kafka 消费者从主题分区中获取的消息记录,它包含了消息的关键信息,如主题、分区、偏移量、键值对等等。
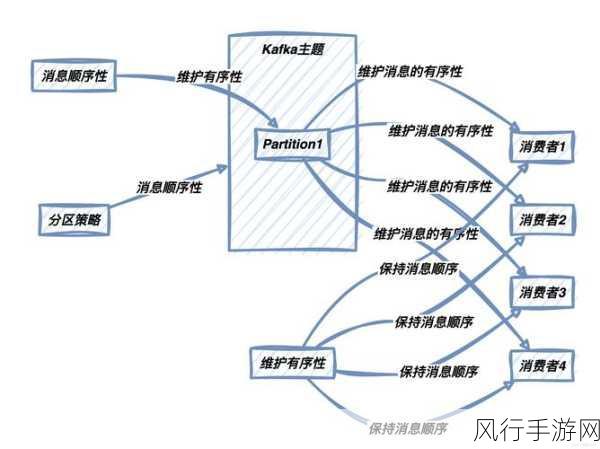
ConsumerRecord 能否被持久化呢?答案是在一定条件下是可以的,我们可以通过将 ConsumerRecord 中的数据存储到外部的数据库、文件系统或者其他持久化存储介质中来实现持久化。
在实际应用中,实现 ConsumerRecord 的持久化具有多种用途,当我们需要对历史数据进行回溯分析,或者需要将消费到的数据进行长期保存以备后续处理时,持久化就显得尤为重要。
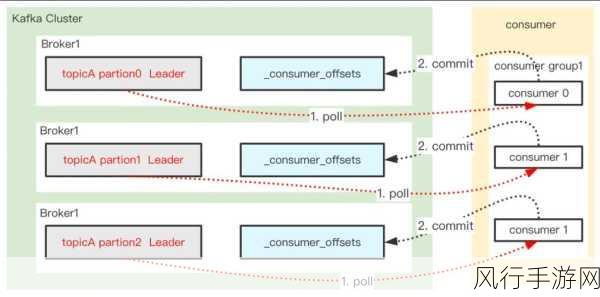
实现 ConsumerRecord 的持久化并非毫无挑战,其中一个关键问题是如何确保数据的一致性和完整性,在将 ConsumerRecord 持久化的过程中,可能会遇到网络延迟、存储故障等各种异常情况,这就需要我们设计合理的错误处理机制和数据恢复策略。
持久化还需要考虑性能方面的影响,大量的 ConsumerRecord 数据持久化操作可能会对系统的性能造成一定的压力,因此需要在存储方案的选择、数据压缩、索引优化等方面进行精心设计,以平衡持久化的需求和系统的性能。
数据的安全性也是持久化过程中不可忽视的一个方面,我们需要采取适当的加密措施来保护持久化的数据,防止数据泄露和未经授权的访问。
Kafka ConsumerRecord 在合适的技术架构和策略下是能够进行持久化的,但在实现过程中,需要充分考虑数据一致性、完整性、性能和安全性等多方面的因素,以确保持久化方案的有效和可靠,只有这样,我们才能充分发挥 Kafka 的优势,满足各种复杂业务场景的需求。