在 Rust 编程语言的世界中,derive 特性无疑是一项强大且实用的功能,它能够为开发者自动生成一些常见的代码逻辑,极大地提高了开发效率,值得注意的是,rust derive 在不同的编译器上可能会呈现出不同的表现。
Rust 编译器的多样性为开发者提供了更多选择,但同时也带来了一些潜在的挑战,不同的编译器对于rust derive 的处理方式可能存在细微的差异,这可能会影响到代码的编译结果和运行时行为。
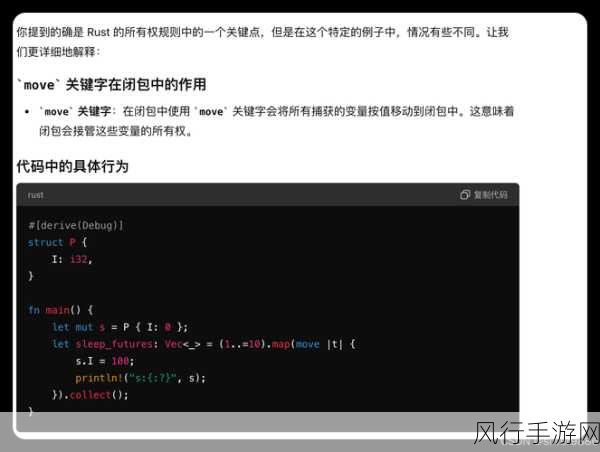
某些编译器可能对于特定的derive 宏有着更严格的语法检查,或者在生成代码的优化方面采取了不同的策略,这就要求开发者在使用rust derive 时,需要对所选用的编译器有一定的了解和认识。
不同编译器对于rust derive 所依赖的标准库和外部库的处理也可能有所不同,这可能会导致在一个编译器上能够正常工作的derive 代码,在另一个编译器上出现编译错误或者运行时异常。
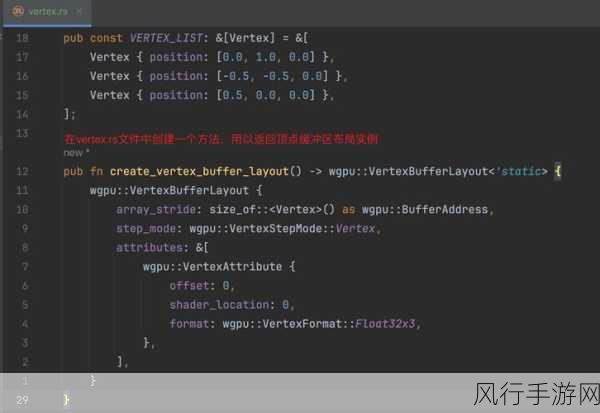
为了更好地应对这种情况,开发者可以采取一些有效的措施,要仔细阅读所选用编译器的文档,了解其对于rust derive 的支持情况和特殊要求,在进行跨编译器的项目开发时,进行充分的测试是必不可少的,通过在多个编译器上进行测试,可以及早发现并解决由于编译器差异导致的问题。
虽然rust derive 为 Rust 开发带来了极大的便利,但在面对不同编译器时,开发者需要保持警惕,充分了解和适应其差异,以确保代码的正确性和稳定性,只有这样,才能充分发挥 Rust 语言的优势,构建出高质量的应用程序。