在当今数字化时代,数据的规模和复杂性呈爆炸式增长,大数据处理成为了众多领域的关键挑战,而 Python 作为一种功能强大且广泛应用的编程语言,许多人会产生疑问:运行 Python 文件能处理大数据吗?答案是肯定的,但也需要考虑一些关键因素。
Python 拥有丰富的库和工具,为大数据处理提供了有力的支持,Pandas 库用于数据读取、清理和预处理;NumPy 库提供了高效的数值计算能力;而 Spark 与 Python 的结合更是为大规模数据处理带来了高效的解决方案。
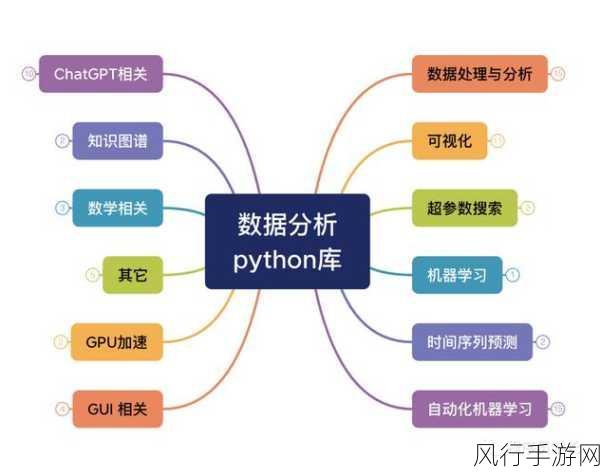
要有效地使用 Python 处理大数据,并非仅仅依靠语言本身,硬件资源的配置至关重要,处理大规模数据时,充足的内存、强大的 CPU 以及高速的存储设备能够显著提升处理效率。
算法和数据结构的选择也影响着大数据处理的性能,合理地运用合适的数据结构,如哈希表、树结构等,可以优化数据的存储和检索,减少处理时间。
对于大规模的数据,分布式计算框架的运用是必不可少的,像 Hadoop 这样的框架可以将计算任务分布在多个节点上并行处理,从而大大提高处理速度。
在实际应用中,还需要对数据进行合理的分区和分块,以便更好地管理和处理,代码的优化也是一个持续的过程,需要不断地进行性能测试和改进。
运行 Python 文件能够处理大数据,但需要综合考虑硬件资源、算法选择、分布式框架的运用以及代码优化等多个方面,只有在这些因素的协同作用下,才能充分发挥 Python 在大数据处理中的优势,为解决实际问题提供有效的支持。
需要注意的是,不同的应用场景和数据特点可能需要不同的技术组合和优化策略,在进行大数据处理时,要根据具体情况进行深入分析和实践,找到最适合的解决方案。