Python 网络爬虫技术作为获取网络数据的有效手段,其爬虫架构的设计至关重要,一个良好的爬虫架构能够提高数据抓取的效率、稳定性和可扩展性。
要设计出高效的 Python 网络爬虫架构,我们需要充分考虑多方面的因素,首先是目标网站的特点和结构,不同的网站可能具有不同的页面布局、反爬虫机制以及数据存储方式,在对目标网站进行深入分析后,我们可以针对性地制定爬虫策略,例如选择合适的请求方式、处理验证码、设置合理的请求频率等。
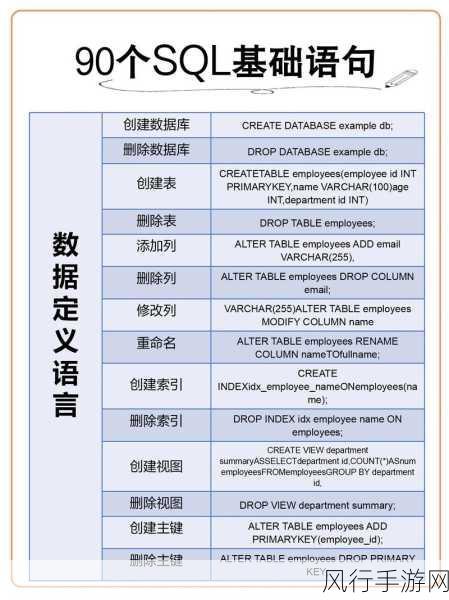
数据存储也是爬虫架构中不可忽视的一环,常见的数据存储方式包括关系型数据库(如 MySQL)、非关系型数据库(如 MongoDB)以及文件存储(如 CSV、JSON 等),根据数据的规模、结构和后续的使用需求,选择合适的数据存储方案能够优化数据的读写性能,提高爬虫的整体效率。
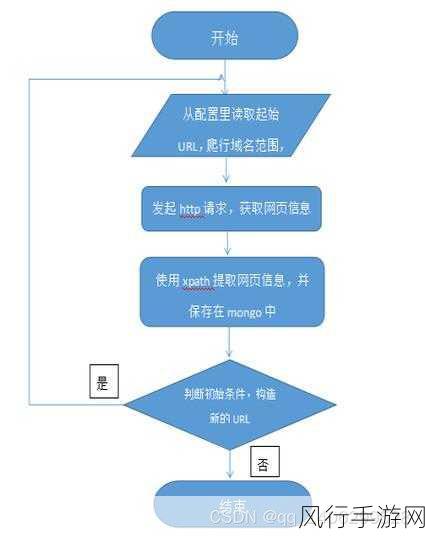
任务调度也是爬虫架构中的关键组成部分,通过合理的任务调度,可以确保爬虫能够有序地抓取网页,避免重复抓取和遗漏,任务调度还需要考虑到网络延迟、服务器负载等因素,以保证爬虫的稳定性和可靠性。
在设计爬虫架构时,还需要注重代码的可读性和可维护性,清晰的代码结构、规范的命名以及详细的注释能够让开发者更容易理解和修改代码,提高开发效率,降低维护成本。
为了应对复杂的网络环境和不断变化的网站规则,爬虫架构应具备良好的容错机制和更新机制,当遇到网络异常、页面解析错误等情况时,爬虫能够自动进行错误处理和重试,保证数据抓取的完整性,随着网站规则的更新,爬虫架构也能够及时进行调整和优化,以适应新的抓取需求。
设计一个优秀的 Python 网络爬虫架构需要综合考虑目标网站特点、数据存储、任务调度、代码质量以及容错更新等多个方面,只有在充分了解和掌握这些要素的基础上,我们才能打造出高效、稳定、可扩展的网络爬虫,为数据获取和分析提供有力支持。