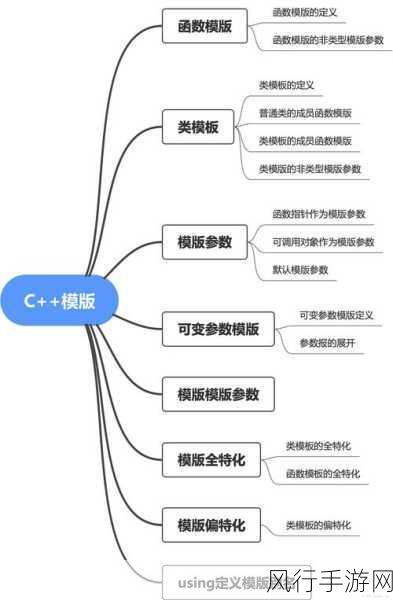
Hadoop 生态系统在当今大数据领域中占据着举足轻重的地位,其对多种数据类型的支持能力更是令人瞩目。
Hadoop 生态系统之所以能够出色地支持多种数据类型,关键在于其架构的灵活性和组件的丰富性,从结构化数据到非结构化数据,从文本到图像、音频、视频等多媒体数据,Hadoop 都能应对自如。
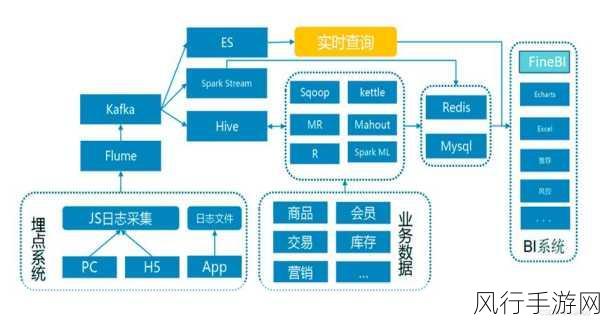
以结构化数据为例,像关系型数据库中的表格数据,Hadoop 可以通过 Hive 组件进行处理和分析,Hive 提供了类似于 SQL 的查询语言,让熟悉传统数据库操作的用户能够轻松上手,将复杂的大数据处理任务转化为简洁明了的查询语句。
对于非结构化数据,比如大量的文本文件,Hadoop 的 MapReduce 框架发挥了重要作用,通过将数据分割成小块,并在多个节点上并行处理,能够高效地提取文本中的关键信息。
多媒体数据的处理则依靠 Hadoop 生态中的其他专门组件,对于图像数据,可以使用基于深度学习的框架与 Hadoop 集成,实现图像的识别和分类,音频和视频数据也能通过特定的算法和工具进行处理和分析。
Hadoop 生态系统还支持实时数据和流数据的处理,通过与 Flink 等流处理框架的结合,能够实现对实时产生的数据进行快速处理和响应,满足诸如在线监测、实时推荐等应用场景的需求。
在数据存储方面,Hadoop 的分布式文件系统 HDFS 提供了强大的底层支持,无论数据的类型和规模如何,HDFS 都能确保数据的可靠存储和高效访问。
Hadoop 生态系统凭借其全面而强大的功能,为处理多种数据类型提供了坚实的基础和高效的解决方案,在大数据时代,这种对多样化数据类型的支持能力使得企业和组织能够更充分地挖掘数据的价值,做出更明智的决策,推动业务的发展和创新。