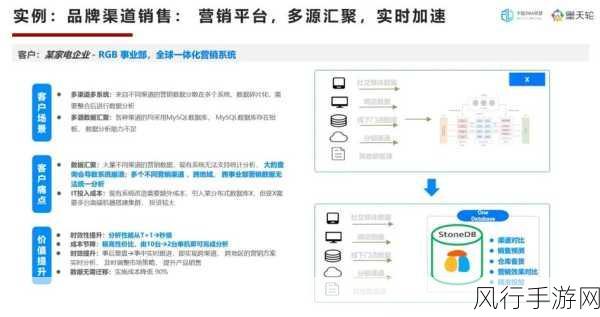
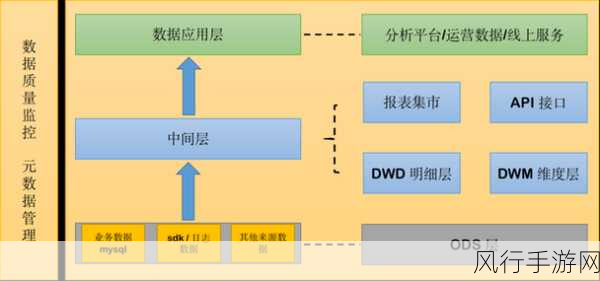
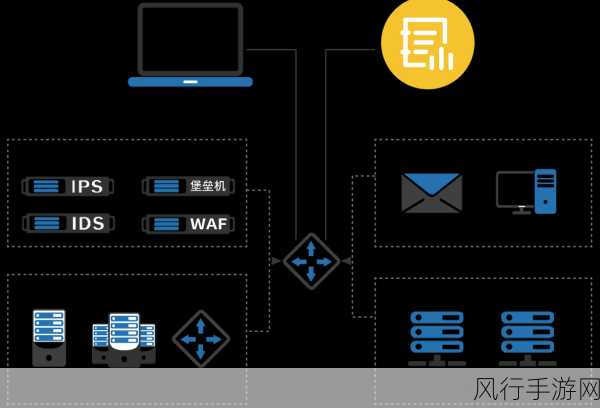
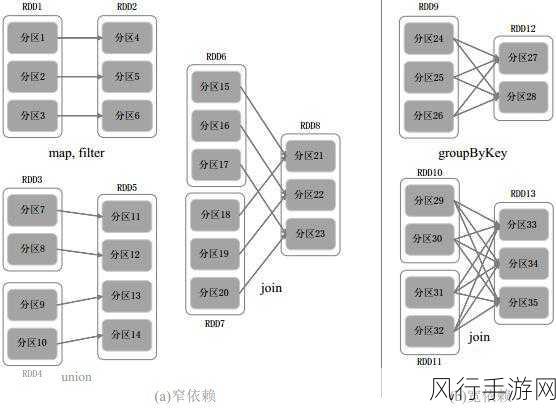
在当今大数据处理领域,Spark 框架无疑是备受瞩目的明星,当我们面临 Spark2 和 Spark3 这两个版本时,可靠性成为了众多开发者和用户关注的焦点,究竟哪一个版本更可靠呢?
Spark3 在性能和优化方面进行了显著的改进,它引入了自适应查询执行(Adaptive Query Execution)等新特性,能够根据运行时的统计信息动态调整执行计划,从而提高查询的效率和可靠性,相比之下,Spark2 虽然也具备出色的性能,但在某些复杂场景下可能不如 Spark3 那样灵活和智能。
从数据处理的准确性来看,Spark3 对于数据类型的处理更加严格和精确,这意味着在处理大规模数据时,减少了因数据类型不匹配或错误导致的异常情况,进一步提升了数据处理的可靠性,而 Spark2 在这方面可能存在一些细微的不足,需要开发者更加谨慎地处理数据类型。
再看资源管理方面,Spark3 对资源的分配和管理更加精细和高效,它能够更好地适应不同的工作负载,合理分配内存和 CPU 资源,避免了资源的浪费和过度竞争,相比之下,Spark2 的资源管理机制相对简单,可能在处理高并发和大规模任务时出现资源瓶颈。

Spark3 在错误处理和恢复机制上也有所加强,当遇到故障或错误时,能够更快地恢复执行,减少了数据丢失和任务中断的风险,而 Spark2 在面对一些严重错误时,恢复的过程可能较为复杂和耗时。
我们不能简单地认为 Spark3 就一定在所有方面都比 Spark2 更可靠,在实际应用中,还需要考虑到具体的业务需求、技术团队的熟悉程度以及现有系统的兼容性等因素。
如果您的业务场景对性能和准确性要求极高,并且技术团队有足够的能力和时间来适应新版本,那么选择 Spark3 可能是一个明智的决策,但如果您的系统已经在稳定运行 Spark2,并且对现有功能和可靠性已经满足需求,那么贸然升级到 Spark3 可能会带来不必要的风险和成本。
Spark3 在许多方面展现出了更高的可靠性和性能优势,但选择哪个版本还需根据具体情况进行综合评估和权衡,只有在充分了解自身需求和技术环境的基础上,才能做出最适合的选择,确保大数据处理的稳定和高效。