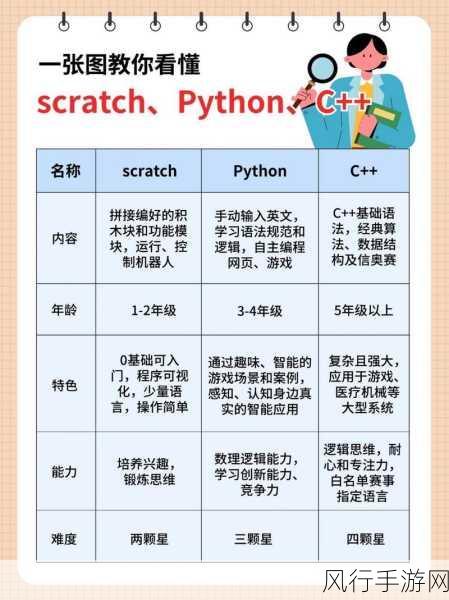
C 语言作为一门经典的编程语言,在许多领域都有着广泛的应用,在实际的编程过程中,我们可能会遇到需要实现类似 set 的排序功能的情况。
要在 C 语言中实现类似 set 的排序功能,并非一件简单的事情,这需要我们对数据结构和算法有深入的理解。

我们先来了解一下 set 的特点,set 是一种集合数据结构,其中的元素具有唯一性,并且通常是按照某种特定的顺序进行存储和排序的。
那么在 C 语言中,我们可以考虑使用数组或者链表来实现类似的功能,如果使用数组,我们需要在插入元素时进行查重操作,确保数组中不存在相同的元素,在排序时可以选择常见的排序算法,如冒泡排序、插入排序、快速排序等。
以冒泡排序为例,其基本思想是通过相邻元素的比较和交换,将最大的元素逐步“浮”到数组的末尾,在实现类似 set 的排序功能时,我们可以在每次比较和交换的过程中,同时检查是否存在重复元素。
如果选择链表来实现,插入元素时查重的操作相对复杂一些,但链表在动态添加和删除元素时具有优势,在排序方面,可以通过修改链表节点的指针来实现排序。
在实际编程中,还需要考虑代码的效率和可读性,在选择排序算法时,要根据数据量的大小和特点来选择合适的算法,对于较小的数据量,冒泡排序可能就足够高效;而对于较大的数据量,快速排序可能更加合适。
为了提高代码的可维护性和可扩展性,我们可以将排序和查重的功能封装成独立的函数,以便在不同的项目中复用。
在 C 语言中实现类似 set 的排序功能需要我们综合运用数据结构和算法的知识,同时注重代码的质量和效率,通过不断地实践和优化,我们能够编写出高效、可靠的代码来满足实际需求。